
Axel Naumann on
Hi!
Build systems belong to the world's most irrelevant things. That is: if they work: if they rebuild the parts that depend on a change, if they work for all platforms, and if they are fast. We are pretty happy with our unspectacular configure && make build system: it gets the dependencies right, and (thanks to cygwin) works on all platforms. But how does it do in terms of speed?
I was told about a $0 (not open source) tool called SparkBuild which analyzes how the build system spends its (real) time. I ran it on our Makefile. Ideally, all the time would be spent in compilation, linking and dictionary generation.
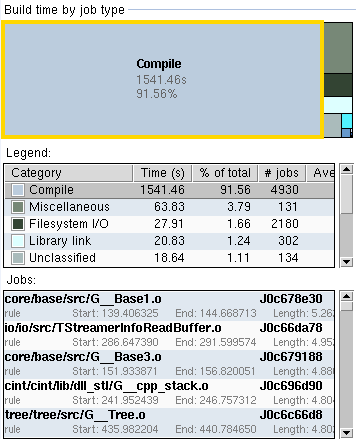
SparkBuild tells me that our Makefile spends 92% in compilation and 1% in linking. 4% of the real time is spent in generating the dictionaries. Another 1% is spent in configuring the separate build systems of unuran, afterimage and xrootd.
Those are amazing numbers. I would be curious to see numbers of other packages, e.g. those using autotools, or CMT: if you are as curious as me, send me some numbers, please! You can run SparkBuild as
$ emake --emake-annodetail=basic,waiting,env --emake-emulation=gmake3.81 -j4 > out.xml
$ /build/local/SparkBuild/i686_Linux/bin/sbinsight out.xml
So why is this relevant, except for reducing the time by a few percent? It matters a lot when you do in-RAM compilation (like I do :-) and you care about using all your cores. Given the numbers SparkBuild extracted it can estimate how long the build would take (assuming e.g. infinite I/O capabilities). If there are long sub-processes, and if these processes are started near the end of the build, then make won't accelerate even if you run it with more parallel processes: the slowest one will define the time (see e.g. PROOF vs. GRID / batch scheduling).
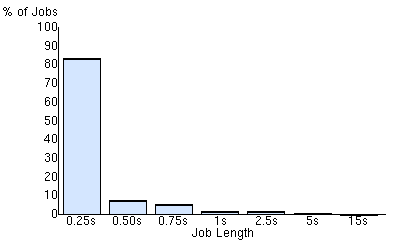
Most of ROOT's build processes are tiny. Because we have them in one big (non-recursive) Makefile, make can distribute these tiny jobs as it wants. With recursive Makefiles, the top-level is only done when the sub-make is finished.
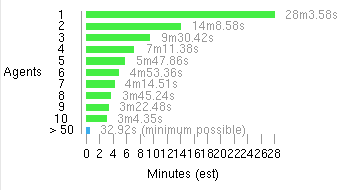
And that means we scale like mad! Even if these numbers are probably unrealistic, they give an impression of how well our build system behaves. I guess we'll continue to use it for a while (but might add a CMake option - who knows :-).
Cheers,