
Axel Naumann on
Hi!
Since version 5.26, ROOT's files are much faster to read; reports regarding ATLAS AODs regularly show a factor 6 speedup. I will explain where this acceleration comes from (or better what stopped previous ROOT files from being that fast) and how you can enable it. Disclaimer: almost all of what I describe here was done by Rene; I only describe his findings and solutions.
Diagnosis
ROOT v5.26 has a new tool that monitors the performance of reading TTrees: TTreePerfStat. Is is used like this:
TFile *f = TFile::Open("xyz.root");
T = (TTree*)f->Get("MyTree");
TTreePerfStats *ps =
new TTreePerfStats("ioperf",T);
Long64_t n = T->GetEntries();
for (Long64_t i = 0;i < n; ++i) {
GetEntry(i);
DoSomething();
}
ps->SaveAs("perfstat.root");
When running that e.g. on "old" ATLAS files, one can see the following distribution:
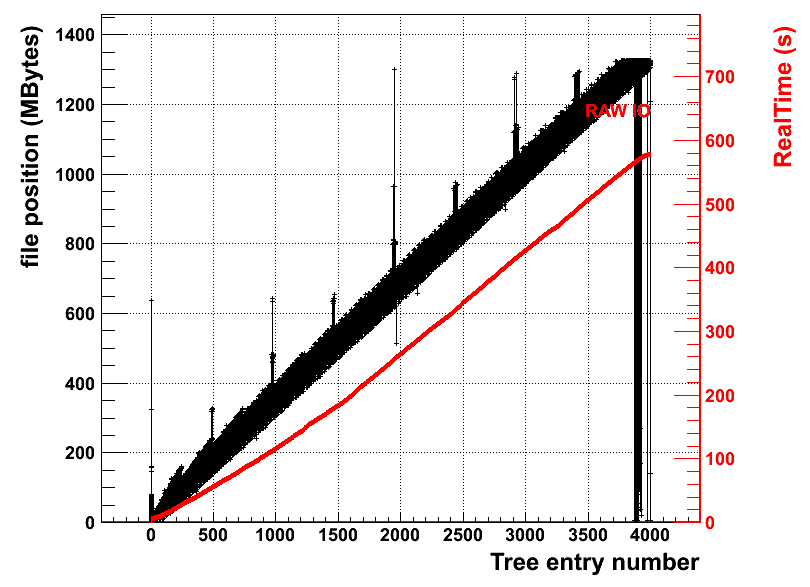
It shows the TTree entry number on the x axis and the file position (in MB) on the y axis (in red: real time). The think black line corresponds to a huge amount of read requests for each TTree entry. If you zoom into one TTree entry you can see the following distribution:
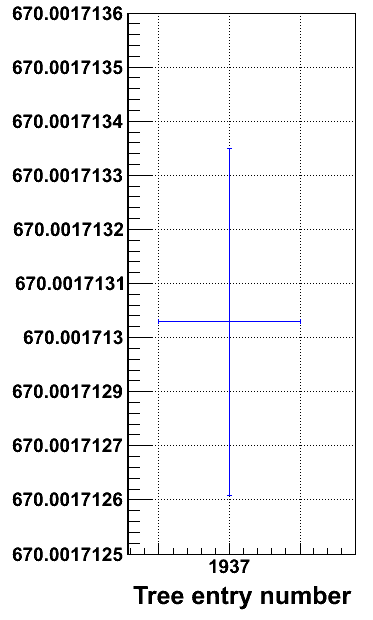
So the problem is clear: for "bad" files, the disk's read heads must be positioned hundreds of times to read one TTree entry. Imagine that you have five people reading from the same disk, or the transfers being requested via a network with a few tens or even hundreds of milliseconds latency: I/O comes to a grinding halt.
The many non-consecutive read requests for a TTree entry stem from the fact that the branches are spread over the file. A branch's data is stored in baskets. Full baskets are written to file when enough data has been entered into the branch. If you have a branch with tiny objects that are only filled once every ten TTree entries then that branch's basket might only get written and the end of the file, when closing it. A "thick" branch with a big object that gets filled every time will be full a lot earlier, resulting in maybe one basket being written for each TTree entry. When reading a TTree entry, ROOT thus needs to jump through the file to load the corresponding baskets, wherever they have been written. OK, problem diagnosed, but what's the pill?
There are three ingredients to the rescue package:
- optimization of TTree basket sizes
- merging of read requests
- read-ahead
Optimization of TTree basket sizes
The baskets' size can be set when creating the branch; most people leave it at the default value. Ideally you would want all baskets to be written for every TTree entry, so a TTree entry's data is consecutive in the TFile, and ROOT can just read a whole block at once. To do that, the baskets' sizes need to be "just right".
ROOT now automatically optimizes the baskets' sizes and flushes the baskets at regular intervals. Because of the read-ahead, ROOT effectively now reads a consecutive block of data when accessing a TTree entry.
Merging of Read Requests
If ROOT needs to read bytes 1001 to 1234 for one basket, bytes 1456 to 1500 for another, and bytes 1235 to 1455 for a third, then it will now simply ask the OS to deliver bytes 1001 to 1500: it merges the requests. If two read requests leave a gap of a few bytes it of course doesn't care, and still requests the full range. This reduces the number of read requests considerably.
Read-Ahead
Reading a TTree usually means reading a subset of branches. ROOT cannot tell which branches are going to be read (you could write something like
tree->GetBranch(">GetEntry(i)
in a rarely executed if statement), but it can guess based on what happened during the analysis of the previous TTree entries. This is used to read the next TTree entry for the predicted branches while the current TTree entry is still analyzed. The I/O thus happens in parallel, and the analysis doesn't need to wait to be able to analyze the next event: the data is already there.
Results
When using all these improvements, the same data as in the previous pictures now looks like this:
You can tell how nice the new ROOT file layout matches what disks want:
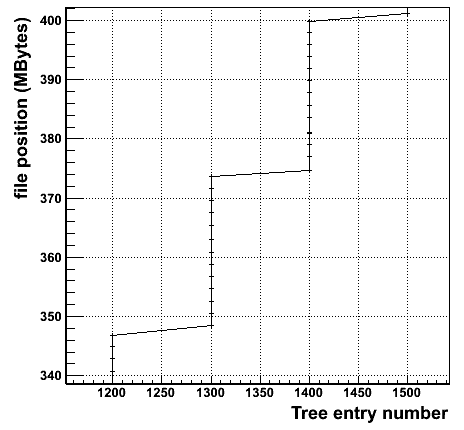
Read requests are consecutive, one read gets data for several entries, and as a result the total number of requests shrinks dramatically. This is not a question of perfection: it really makes all the difference when reading files, especially when you are not the only process accessing the disk: studies in CERN's IT department have shown that multi-user concurrent disk access is basically impossible without these optimizations.
How to Turn It On
We'd love to turn it on by default. But the read-ahead needs to put the data somewhere: we need some extra memory; 30 to 100MB are enough. But with the experiments' never ending quest for memory resources turning this on by default is not an option: a 4-core machine with 4 jobs would eat an additional 400MB. Too much.
Instead you need to turn it on by yourself by calling
tree->SetCacheSize(10000000);
tree->AddBranchToCache("*");
for (Int_t i=0;iGetEntry(i);
...
}
;i++)>
The optimization of the basket size and the flushing of the baskets happen automatically. See the release notes for more info.
After so much byte pushing we all need a break: I will report on my trip to northern India in my next entry, showing how I survived vacation and enjoyed ACAT 2010.
Cheers,
Comments
Submitted by Anonymous (not verified) on Sun, 01/15/2012 - 16:23 Permalink
Use case...
Will this affect the read speed if I'm reading old files? (Probably not)
How about the case where I open a file, load a specific entry, and then close the file again? Will there be any substantial speed gain in that case?
Submitted by Anonymous (not verified) on Mon, 01/16/2012 - 16:04 Permalink
Hi Nathaniel,
Hi Nathaniel,
Thanks for your good questions! I would definitely recommend to re-write old files. You could simply call hadd -O betterfile.root oldfile.root which will optimize the tree, given a recent $ROOTSYS/bin/hadd.
You should see any increase in disk speed when reading a single entry when using a new (>= v5-30) ROOT version: CPU time (for building a C++ object out of the data stream read from the ROOT file) is reduced, and the new layout of the data within the file should reduce the disk seek time even when reading only one single entry.
Cheers, Axel
Submitted by Anonymous (not verified) on Thu, 03/11/2010 - 17:04 Permalink
Awesome post, Axel!
Great stuff. I assume this is now the official ROOT documentation on this subject. :)
Submitted by Anonymous (not verified) on Wed, 03/17/2010 - 15:08 Permalink
Re: (*blush*)
Hy Andy!
Thanks :-) Actually it was documented in the release notes. We probably need a tutorial for it, though! Anyone willing to write one? :-)
Cheers, Axel