
RDataFrame is going distributed!
(22 July 2021)So you love RDataFrame, but would like to use it on a cluster? We hear you! In fact, we just introduced in ROOT a Python package to enable distributing ROOT RDataFrame workloads to a set of remote resources. This feature is available in experimental phase since the latest ROOT 6.24 release, allowing users to write and run their applications from within the same interface while steering the computations to, for instance, an Apache Spark cluster.
One programming model, many backends
RDataFrame is ROOT’s high-level interface for data analysis since ROOT v6.14. By now many real world analyses use it, and on top of that we see lots of non-analysis usage in the wild. Parallelism has always been a staple of its design with support for executing the event loop on all cores of a machine thanks to implicit multi-threading. Since ROOT 6.24, this aspect of RDataFrame has been enhanced further with distributed computing capabilities, allowing users to run their analysis on multi-node computing clusters through widely used frameworks. Currently the package offers support for running the application on an Apache Spark cluster, but the package design will make it possible to add many more backends in the future. For example, backends for Dask and AWS Lambda have already been implemented and demonstrated at different conferences [1][2]. They will be made available in future ROOT releases.
The main goal is to support distributed execution of any RDataFrame application. This has led to the creation of a Python package that connects the RDataFrame API (available in Python through PyROOT) and the APIs of distributed computing frameworks, which are offered in Python in the vast majority of cases. Another key goal is to offer a variety of backends, to provide a solution to a variety of use cases. This is achieved through a modular implementation that defines a generic task (representing the RDataFrame computation graph) to be executed on data. The input dataset is logically split into many ranges of entries, which will be sent to the distributed nodes for processing. Each range will then be paired to the generic task and submitted to the computing framework via a specific backend implementation. An added benefit of using RDataFrame is that the distributed tasks run C++ computations. This is made possible by PyROOT and cling.
Excellent scaling is paramount for this distributed RDataFrame implementation, to ensure you can run the RDataFrame computation graph efficiently across multiple computing nodes and different backend implementations. This has been shown since the first stages of the development of this package with a real use case analysis running on a Spark cluster [3]. More recently, a benchmark based on CERN open data has shown promising scaling performance with both Spark and Dask [4]:
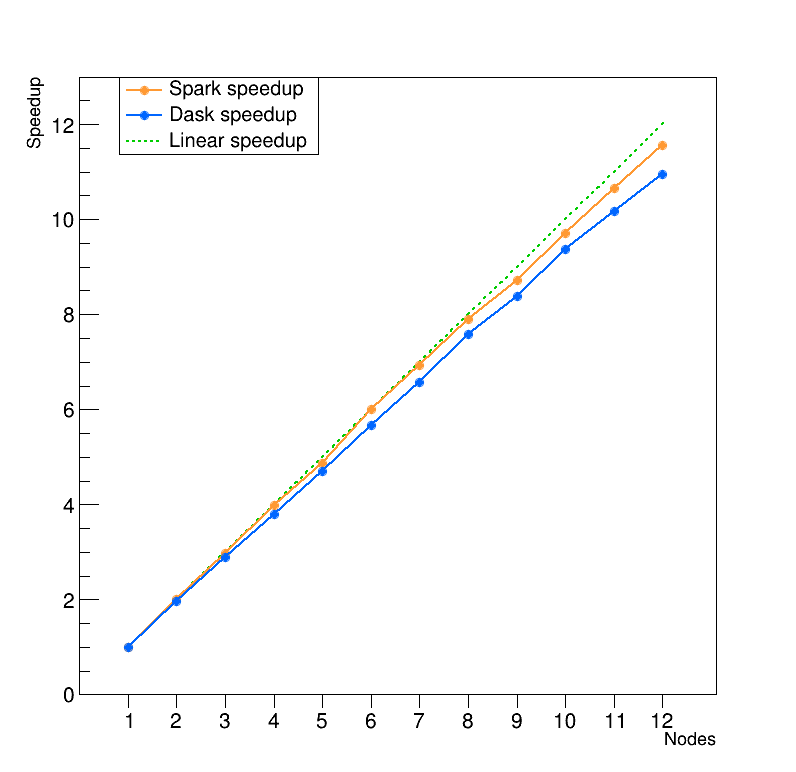
We hear you asking: how does it look in code? Here is an example of an RDataFrame that is able to delegate its
computations to a Spark scheduler (requires the Python pyspark package):
import ROOT
# Point RDataFrame calls to the Spark specific RDataFrame
RDataFrame = ROOT.RDF.Experimental.Distributed.Spark.RDataFrame
# It still accepts the same constructor arguments as traditional RDataFrame.
# It defaults to running a Spark process on the local machine, but it is possible
# to configure the RDataFrame to connect to a preexisting cluster.
df = RDataFrame("mytree", "myfile.root")
# Continue with the traditional RDataFrame API
sum = df.Filter("x > 10").Sum("y")
h = df.Histo1D("x")
print(sum.GetValue())
h.Draw()
The only difference with respect to local RDataFrame was the usage of a Spark backend specific RDataFrame. By default, it runs on the local machine using all cores. That is, it uses the default Spark behaviour. If a cluster is available, distributed RDataFrame allows connections to the remote scheduler through an extra optional argument in the constructor. Here is an example that also shows the connection to a Dask cluster:
from dask.distributed import Client
import ROOT
# Point RDataFrame calls to the Dask specific RDataFrame
RDataFrame = ROOT.RDF.Experimental.Distributed.Dask.RDataFrame
# Create the Client object to connect to the Dask cluster
# See the Dask documentation for all the options available
client = Client("DASK_SCHEDULER_ADDRESS")
# It still accepts the same constructor arguments as traditional RDataFrame
# And supports some extra keyword arguments
df = RDataFrame("mytree", "myfile.root", npartitions = 8, daskclient = client)
In this example the npartitions parameter tells the RDataFrame into how many ranges of entries the input dataset should
be split. Each range will then correspond to a task on a node of the cluster. The daskclient parameter receives the
object needed to connect to the Dask scheduler. All the options are available in the
Dask documentation. The equivalent object for the Spark framework
is called SparkContext and in
general every backend will have its own way to connect to a cluster of nodes.
Once the correct RDataFrame object has been created, there is no need to modify any other part of the program.
Conclusions
Distributed RDataFrame enables large-scale interactive data analysis with ROOT. This Python layer on top of RDataFrame allows to steer C++ computations on a set of computing nodes and returning the final result directly to the user, so that the entire analysis can be run within the same application. It is available as an experimental feature since ROOT 6.24 with the support for running on a Spark cluster, with more backends in the works: Dask will be available soon in our nightly builds. Try distributed RDataFrame with our tutorial tutorial and learn more about it in the respective RDataFrame documentation section.
References
[1] Vincenzo Eduardo Padulano, Enric Tejedor Saavedra. “Dask backend for distributed RDataFrame”. In: Dask Distributed Summit 2021. https://summit.dask.org/schedule/presentation/24/dask-in-high-energy-physics-community
[2] Jacek Kusnierz et al. “Distributed Parallel Analysis Engine for High Energy Physics Using AWS Lambda”. In: HPDC 2021. https://dl.acm.org/doi/10.1145/3452413.3464788
[3] Valentina Avati et al. “Declarative Big Data Analysis for High-Energy Physics: TOTEM Use Case”. In:Euro-Par 2019: Parallel Processing (2019),pp. 241–255. https://doi.org/10.1007/978-3-030-29400-7_18
[4] Vincenzo Eduardo Padulano, Enric Tejedor Saavedra. “A Python package for distributed ROOT RDataFrame analysis”. In: PyHEP 2021. https://indico.cern.ch/event/1019958/contributions/4419751