 |
ROOT
Reference Guide |

|
| |
ROOT
Reference Guide |
|

![]()
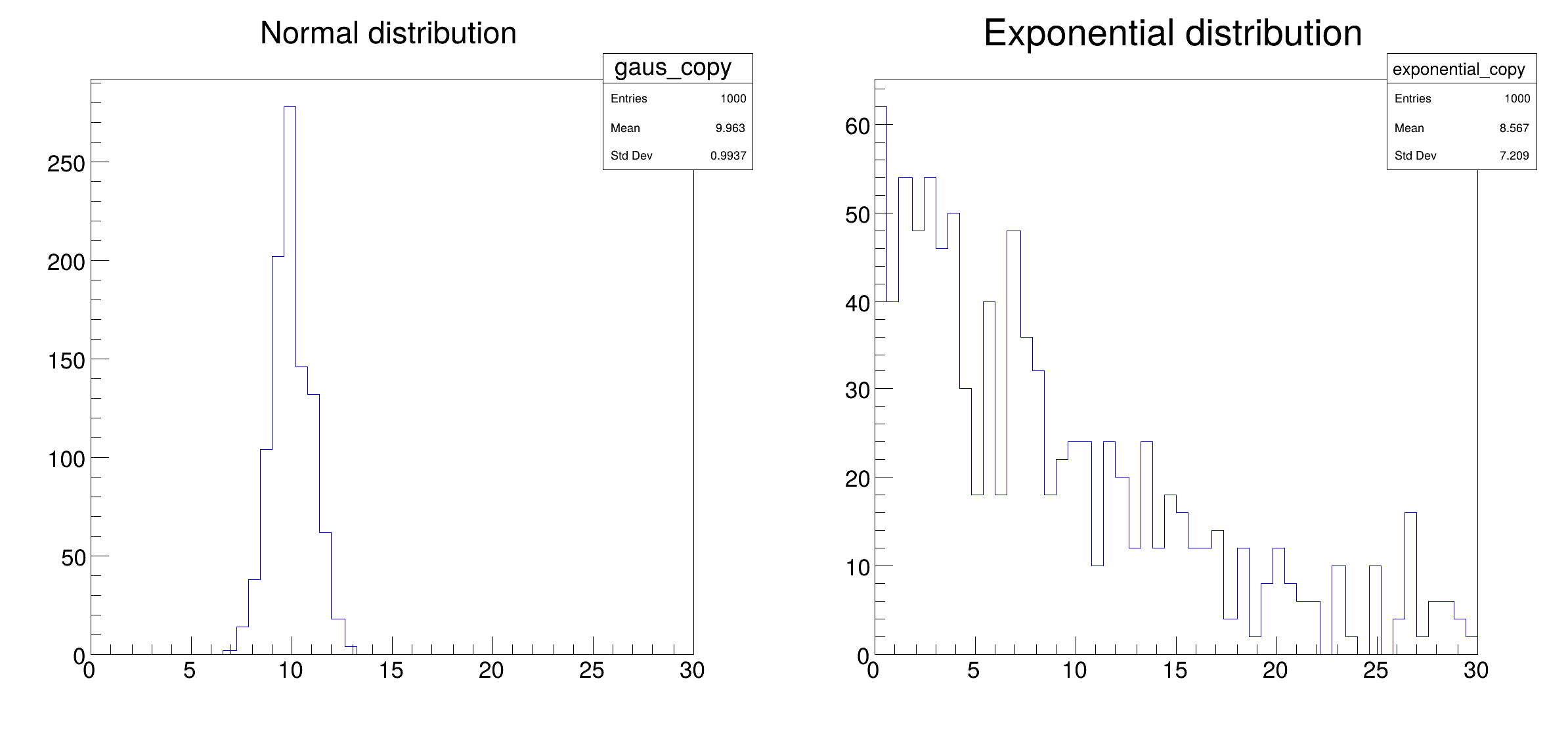
Configure a Spark connection and fill two histograms distributedly.
This tutorial shows the ingredients needed to setup the connection to a Spark cluster, namely a SparkConf object holding configuration parameters and a SparkContext object created with the desired options. After this initial setup, an RDataFrame with distributed capabilities is created and connected to the SparkContext instance. Finally, a couple of histograms are drawn from the created columns in the dataset.
Definition in file distrdf001_spark_connection.py.
