Running with nthreads = 4
DataSetInfo : [dataset] : Added class "Signal"
: Add Tree sig_tree of type Signal with 1000 events
DataSetInfo : [dataset] : Added class "Background"
: Add Tree bkg_tree of type Background with 1000 events
Factory : Booking method: ␛[1mBDT␛[0m
:
: Rebuilding Dataset dataset
: Building event vectors for type 2 Signal
: Dataset[dataset] : create input formulas for tree sig_tree
: Using variable vars[0] from array expression vars of size 256
: Building event vectors for type 2 Background
: Dataset[dataset] : create input formulas for tree bkg_tree
: Using variable vars[0] from array expression vars of size 256
DataSetFactory : [dataset] : Number of events in input trees
:
:
: Number of training and testing events
: ---------------------------------------------------------------------------
: Signal -- training events : 800
: Signal -- testing events : 200
: Signal -- training and testing events: 1000
: Background -- training events : 800
: Background -- testing events : 200
: Background -- training and testing events: 1000
:
Factory : Booking method: ␛[1mTMVA_DNN_CPU␛[0m
:
: Parsing option string:
: ... "!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=None:WeightInitialization=XAVIER:Layout=DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,DENSE|1|LINEAR:TrainingStrategy=LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.:Architecture=CPU"
: The following options are set:
: - By User:
: <none>
: - Default:
: Boost_num: "0" [Number of times the classifier will be boosted]
: Parsing option string:
: ... "!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=None:WeightInitialization=XAVIER:Layout=DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,DENSE|1|LINEAR:TrainingStrategy=LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.:Architecture=CPU"
: The following options are set:
: - By User:
: V: "True" [Verbose output (short form of "VerbosityLevel" below - overrides the latter one)]
: VarTransform: "None" [List of variable transformations performed before training, e.g., "D_Background,P_Signal,G,N_AllClasses" for: "Decorrelation, PCA-transformation, Gaussianisation, Normalisation, each for the given class of events ('AllClasses' denotes all events of all classes, if no class indication is given, 'All' is assumed)"]
: H: "False" [Print method-specific help message]
: Layout: "DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,DENSE|1|LINEAR" [Layout of the network.]
: ErrorStrategy: "CROSSENTROPY" [Loss function: Mean squared error (regression) or cross entropy (binary classification).]
: WeightInitialization: "XAVIER" [Weight initialization strategy]
: Architecture: "CPU" [Which architecture to perform the training on.]
: TrainingStrategy: "LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0." [Defines the training strategies.]
: - Default:
: VerbosityLevel: "Default" [Verbosity level]
: CreateMVAPdfs: "False" [Create PDFs for classifier outputs (signal and background)]
: IgnoreNegWeightsInTraining: "False" [Events with negative weights are ignored in the training (but are included for testing and performance evaluation)]
: InputLayout: "0|0|0" [The Layout of the input]
: BatchLayout: "0|0|0" [The Layout of the batch]
: RandomSeed: "0" [Random seed used for weight initialization and batch shuffling]
: ValidationSize: "20%" [Part of the training data to use for validation. Specify as 0.2 or 20% to use a fifth of the data set as validation set. Specify as 100 to use exactly 100 events. (Default: 20%)]
: Will now use the CPU architecture with BLAS and IMT support !
Factory : Booking method: ␛[1mTMVA_CNN_CPU␛[0m
:
: Parsing option string:
: ... "!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=None:WeightInitialization=XAVIER:InputLayout=1|16|16:Layout=CONV|10|3|3|1|1|1|1|RELU,BNORM,CONV|10|3|3|1|1|1|1|RELU,MAXPOOL|2|2|1|1,RESHAPE|FLAT,DENSE|100|RELU,DENSE|1|LINEAR:TrainingStrategy=LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.0:Architecture=CPU"
: The following options are set:
: - By User:
: <none>
: - Default:
: Boost_num: "0" [Number of times the classifier will be boosted]
: Parsing option string:
: ... "!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=None:WeightInitialization=XAVIER:InputLayout=1|16|16:Layout=CONV|10|3|3|1|1|1|1|RELU,BNORM,CONV|10|3|3|1|1|1|1|RELU,MAXPOOL|2|2|1|1,RESHAPE|FLAT,DENSE|100|RELU,DENSE|1|LINEAR:TrainingStrategy=LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.0:Architecture=CPU"
: The following options are set:
: - By User:
: V: "True" [Verbose output (short form of "VerbosityLevel" below - overrides the latter one)]
: VarTransform: "None" [List of variable transformations performed before training, e.g., "D_Background,P_Signal,G,N_AllClasses" for: "Decorrelation, PCA-transformation, Gaussianisation, Normalisation, each for the given class of events ('AllClasses' denotes all events of all classes, if no class indication is given, 'All' is assumed)"]
: H: "False" [Print method-specific help message]
: InputLayout: "1|16|16" [The Layout of the input]
: Layout: "CONV|10|3|3|1|1|1|1|RELU,BNORM,CONV|10|3|3|1|1|1|1|RELU,MAXPOOL|2|2|1|1,RESHAPE|FLAT,DENSE|100|RELU,DENSE|1|LINEAR" [Layout of the network.]
: ErrorStrategy: "CROSSENTROPY" [Loss function: Mean squared error (regression) or cross entropy (binary classification).]
: WeightInitialization: "XAVIER" [Weight initialization strategy]
: Architecture: "CPU" [Which architecture to perform the training on.]
: TrainingStrategy: "LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.0" [Defines the training strategies.]
: - Default:
: VerbosityLevel: "Default" [Verbosity level]
: CreateMVAPdfs: "False" [Create PDFs for classifier outputs (signal and background)]
: IgnoreNegWeightsInTraining: "False" [Events with negative weights are ignored in the training (but are included for testing and performance evaluation)]
: BatchLayout: "0|0|0" [The Layout of the batch]
: RandomSeed: "0" [Random seed used for weight initialization and batch shuffling]
: ValidationSize: "20%" [Part of the training data to use for validation. Specify as 0.2 or 20% to use a fifth of the data set as validation set. Specify as 100 to use exactly 100 events. (Default: 20%)]
: Will now use the CPU architecture with BLAS and IMT support !
Factory : ␛[1mTrain all methods␛[0m
Factory : Train method: BDT for Classification
:
BDT : #events: (reweighted) sig: 800 bkg: 800
: #events: (unweighted) sig: 800 bkg: 800
: Training 200 Decision Trees ... patience please
: Elapsed time for training with 1600 events: 0.669 sec
BDT : [dataset] : Evaluation of BDT on training sample (1600 events)
: Elapsed time for evaluation of 1600 events: 0.00629 sec
: Creating xml weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_BDT.weights.xml␛[0m
: Creating standalone class: ␛[0;36mdataset/weights/TMVA_CNN_Classification_BDT.class.C␛[0m
: TMVA_CNN_ClassificationOutput.root:/dataset/Method_BDT/BDT
Factory : Training finished
:
Factory : Train method: TMVA_DNN_CPU for Classification
:
: Start of deep neural network training on CPU using MT, nthreads = 4
:
: ***** Deep Learning Network *****
DEEP NEURAL NETWORK: Depth = 8 Input = ( 1, 1, 256 ) Batch size = 100 Loss function = C
Layer 0 DENSE Layer: ( Input = 256 , Width = 100 ) Output = ( 1 , 100 , 100 ) Activation Function = Relu
Layer 1 BATCH NORM Layer: Input/Output = ( 100 , 100 , 1 ) Norm dim = 100 axis = -1
Layer 2 DENSE Layer: ( Input = 100 , Width = 100 ) Output = ( 1 , 100 , 100 ) Activation Function = Relu
Layer 3 BATCH NORM Layer: Input/Output = ( 100 , 100 , 1 ) Norm dim = 100 axis = -1
Layer 4 DENSE Layer: ( Input = 100 , Width = 100 ) Output = ( 1 , 100 , 100 ) Activation Function = Relu
Layer 5 BATCH NORM Layer: Input/Output = ( 100 , 100 , 1 ) Norm dim = 100 axis = -1
Layer 6 DENSE Layer: ( Input = 100 , Width = 100 ) Output = ( 1 , 100 , 100 ) Activation Function = Relu
Layer 7 DENSE Layer: ( Input = 100 , Width = 1 ) Output = ( 1 , 100 , 1 ) Activation Function = Identity
: Using 1280 events for training and 320 for testing
: Compute initial loss on the validation data
: Training phase 1 of 1: Optimizer ADAM (beta1=0.9,beta2=0.999,eps=1e-07) Learning rate = 0.001 regularization 0 minimum error = 40.8264
: --------------------------------------------------------------
: Epoch | Train Err. Val. Err. t(s)/epoch t(s)/Loss nEvents/s Conv. Steps
: --------------------------------------------------------------
: Start epoch iteration ...
: 1 Minimum Test error found - save the configuration
: 1 | 1.07643 0.970466 0.10267 0.0102744 12987.6 0
: 2 Minimum Test error found - save the configuration
: 2 | 0.686185 0.880241 0.102652 0.0100706 12961.6 0
: 3 Minimum Test error found - save the configuration
: 3 | 0.617199 0.836282 0.102324 0.010099 13011.6 0
: 4 Minimum Test error found - save the configuration
: 4 | 0.514575 0.817992 0.102549 0.0101051 12980.9 0
: 5 | 0.480063 2.46706 0.102126 0.00979623 12996.9 1
: 6 | 0.410904 0.848345 0.102224 0.0097345 12974.4 2
: 7 | 0.363683 0.81986 0.102142 0.00980999 12996.6 3
: 8 Minimum Test error found - save the configuration
: 8 | 0.308381 0.801552 0.102408 0.0100704 12995.8 0
: 9 | 0.275496 0.873844 0.102118 0.00980334 12999.1 1
: 10 | 0.235943 3.3466 0.102205 0.00977011 12982.2 2
:
: Elapsed time for training with 1600 events: 1.04 sec
: Evaluate deep neural network on CPU using batches with size = 100
:
TMVA_DNN_CPU : [dataset] : Evaluation of TMVA_DNN_CPU on training sample (1600 events)
: Elapsed time for evaluation of 1600 events: 0.0508 sec
: Creating xml weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_DNN_CPU.weights.xml␛[0m
: Creating standalone class: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_DNN_CPU.class.C␛[0m
Factory : Training finished
:
Factory : Train method: TMVA_CNN_CPU for Classification
:
: Start of deep neural network training on CPU using MT, nthreads = 4
:
: ***** Deep Learning Network *****
DEEP NEURAL NETWORK: Depth = 7 Input = ( 1, 16, 16 ) Batch size = 100 Loss function = C
Layer 0 CONV LAYER: ( W = 16 , H = 16 , D = 10 ) Filter ( W = 3 , H = 3 ) Output = ( 100 , 10 , 10 , 256 ) Activation Function = Relu
Layer 1 BATCH NORM Layer: Input/Output = ( 10 , 256 , 100 ) Norm dim = 10 axis = 1
Layer 2 CONV LAYER: ( W = 16 , H = 16 , D = 10 ) Filter ( W = 3 , H = 3 ) Output = ( 100 , 10 , 10 , 256 ) Activation Function = Relu
Layer 3 POOL Layer: ( W = 15 , H = 15 , D = 10 ) Filter ( W = 2 , H = 2 ) Output = ( 100 , 10 , 10 , 225 )
Layer 4 RESHAPE Layer Input = ( 10 , 15 , 15 ) Output = ( 1 , 100 , 2250 )
Layer 5 DENSE Layer: ( Input = 2250 , Width = 100 ) Output = ( 1 , 100 , 100 ) Activation Function = Relu
Layer 6 DENSE Layer: ( Input = 100 , Width = 1 ) Output = ( 1 , 100 , 1 ) Activation Function = Identity
: Using 1280 events for training and 320 for testing
: Compute initial loss on the validation data
: Training phase 1 of 1: Optimizer ADAM (beta1=0.9,beta2=0.999,eps=1e-07) Learning rate = 0.001 regularization 0 minimum error = 72.2941
: --------------------------------------------------------------
: Epoch | Train Err. Val. Err. t(s)/epoch t(s)/Loss nEvents/s Conv. Steps
: --------------------------------------------------------------
: Start epoch iteration ...
: 1 Minimum Test error found - save the configuration
: 1 | 2.44287 1.55211 0.746573 0.0658078 1762.72 0
: 2 Minimum Test error found - save the configuration
: 2 | 0.915449 0.779621 0.728725 0.0648066 1807.45 0
: 3 Minimum Test error found - save the configuration
: 3 | 0.736398 0.694355 0.728313 0.0646226 1808.07 0
: 4 | 0.699841 0.735895 0.735763 0.0638553 1785.96 1
: 5 Minimum Test error found - save the configuration
: 5 | 0.688696 0.690282 0.730494 0.0646004 1802.09 0
: 6 Minimum Test error found - save the configuration
: 6 | 0.67786 0.68949 0.729185 0.0648569 1806.34 0
: 7 Minimum Test error found - save the configuration
: 7 | 0.661809 0.682279 0.727299 0.0646954 1811.04 0
: 8 Minimum Test error found - save the configuration
: 8 | 0.65759 0.675603 0.731393 0.0649645 1800.64 0
: 9 Minimum Test error found - save the configuration
: 9 | 0.632803 0.653956 0.737405 0.0649504 1784.51 0
: 10 Minimum Test error found - save the configuration
: 10 | 0.619979 0.63801 0.730655 0.0650512 1802.88 0
:
: Elapsed time for training with 1600 events: 7.4 sec
: Evaluate deep neural network on CPU using batches with size = 100
:
TMVA_CNN_CPU : [dataset] : Evaluation of TMVA_CNN_CPU on training sample (1600 events)
: Elapsed time for evaluation of 1600 events: 0.34 sec
: Creating xml weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_CNN_CPU.weights.xml␛[0m
: Creating standalone class: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_CNN_CPU.class.C␛[0m
Factory : Training finished
:
: Ranking input variables (method specific)...
BDT : Ranking result (top variable is best ranked)
: --------------------------------------
: Rank : Variable : Variable Importance
: --------------------------------------
: 1 : vars : 1.360e-02
: 2 : vars : 1.170e-02
: 3 : vars : 1.109e-02
: 4 : vars : 1.000e-02
: 5 : vars : 9.682e-03
: 6 : vars : 9.521e-03
: 7 : vars : 9.381e-03
: 8 : vars : 9.370e-03
: 9 : vars : 9.082e-03
: 10 : vars : 8.937e-03
: 11 : vars : 8.897e-03
: 12 : vars : 8.803e-03
: 13 : vars : 8.719e-03
: 14 : vars : 8.660e-03
: 15 : vars : 8.382e-03
: 16 : vars : 8.320e-03
: 17 : vars : 8.290e-03
: 18 : vars : 8.240e-03
: 19 : vars : 8.172e-03
: 20 : vars : 7.870e-03
: 21 : vars : 7.794e-03
: 22 : vars : 7.789e-03
: 23 : vars : 7.652e-03
: 24 : vars : 7.607e-03
: 25 : vars : 7.561e-03
: 26 : vars : 7.549e-03
: 27 : vars : 7.471e-03
: 28 : vars : 7.204e-03
: 29 : vars : 7.081e-03
: 30 : vars : 7.062e-03
: 31 : vars : 7.018e-03
: 32 : vars : 7.012e-03
: 33 : vars : 6.851e-03
: 34 : vars : 6.799e-03
: 35 : vars : 6.783e-03
: 36 : vars : 6.722e-03
: 37 : vars : 6.634e-03
: 38 : vars : 6.601e-03
: 39 : vars : 6.565e-03
: 40 : vars : 6.559e-03
: 41 : vars : 6.332e-03
: 42 : vars : 6.316e-03
: 43 : vars : 6.295e-03
: 44 : vars : 6.260e-03
: 45 : vars : 6.247e-03
: 46 : vars : 6.242e-03
: 47 : vars : 6.235e-03
: 48 : vars : 6.233e-03
: 49 : vars : 6.193e-03
: 50 : vars : 6.163e-03
: 51 : vars : 6.056e-03
: 52 : vars : 5.997e-03
: 53 : vars : 5.904e-03
: 54 : vars : 5.852e-03
: 55 : vars : 5.813e-03
: 56 : vars : 5.811e-03
: 57 : vars : 5.748e-03
: 58 : vars : 5.694e-03
: 59 : vars : 5.648e-03
: 60 : vars : 5.643e-03
: 61 : vars : 5.640e-03
: 62 : vars : 5.622e-03
: 63 : vars : 5.607e-03
: 64 : vars : 5.603e-03
: 65 : vars : 5.575e-03
: 66 : vars : 5.546e-03
: 67 : vars : 5.424e-03
: 68 : vars : 5.393e-03
: 69 : vars : 5.329e-03
: 70 : vars : 5.265e-03
: 71 : vars : 5.258e-03
: 72 : vars : 5.244e-03
: 73 : vars : 5.228e-03
: 74 : vars : 5.221e-03
: 75 : vars : 5.199e-03
: 76 : vars : 5.174e-03
: 77 : vars : 5.170e-03
: 78 : vars : 5.081e-03
: 79 : vars : 5.075e-03
: 80 : vars : 5.065e-03
: 81 : vars : 5.038e-03
: 82 : vars : 5.032e-03
: 83 : vars : 4.993e-03
: 84 : vars : 4.973e-03
: 85 : vars : 4.968e-03
: 86 : vars : 4.954e-03
: 87 : vars : 4.950e-03
: 88 : vars : 4.927e-03
: 89 : vars : 4.892e-03
: 90 : vars : 4.881e-03
: 91 : vars : 4.880e-03
: 92 : vars : 4.879e-03
: 93 : vars : 4.869e-03
: 94 : vars : 4.801e-03
: 95 : vars : 4.799e-03
: 96 : vars : 4.782e-03
: 97 : vars : 4.775e-03
: 98 : vars : 4.764e-03
: 99 : vars : 4.737e-03
: 100 : vars : 4.723e-03
: 101 : vars : 4.702e-03
: 102 : vars : 4.702e-03
: 103 : vars : 4.691e-03
: 104 : vars : 4.677e-03
: 105 : vars : 4.650e-03
: 106 : vars : 4.627e-03
: 107 : vars : 4.593e-03
: 108 : vars : 4.590e-03
: 109 : vars : 4.561e-03
: 110 : vars : 4.536e-03
: 111 : vars : 4.524e-03
: 112 : vars : 4.504e-03
: 113 : vars : 4.475e-03
: 114 : vars : 4.447e-03
: 115 : vars : 4.439e-03
: 116 : vars : 4.415e-03
: 117 : vars : 4.384e-03
: 118 : vars : 4.373e-03
: 119 : vars : 4.359e-03
: 120 : vars : 4.358e-03
: 121 : vars : 4.349e-03
: 122 : vars : 4.241e-03
: 123 : vars : 4.208e-03
: 124 : vars : 4.176e-03
: 125 : vars : 4.169e-03
: 126 : vars : 4.123e-03
: 127 : vars : 4.117e-03
: 128 : vars : 4.089e-03
: 129 : vars : 4.054e-03
: 130 : vars : 4.050e-03
: 131 : vars : 4.047e-03
: 132 : vars : 3.979e-03
: 133 : vars : 3.975e-03
: 134 : vars : 3.917e-03
: 135 : vars : 3.836e-03
: 136 : vars : 3.774e-03
: 137 : vars : 3.678e-03
: 138 : vars : 3.619e-03
: 139 : vars : 3.580e-03
: 140 : vars : 3.553e-03
: 141 : vars : 3.506e-03
: 142 : vars : 3.501e-03
: 143 : vars : 3.477e-03
: 144 : vars : 3.476e-03
: 145 : vars : 3.467e-03
: 146 : vars : 3.466e-03
: 147 : vars : 3.451e-03
: 148 : vars : 3.448e-03
: 149 : vars : 3.441e-03
: 150 : vars : 3.398e-03
: 151 : vars : 3.388e-03
: 152 : vars : 3.372e-03
: 153 : vars : 3.332e-03
: 154 : vars : 3.330e-03
: 155 : vars : 3.327e-03
: 156 : vars : 3.249e-03
: 157 : vars : 3.234e-03
: 158 : vars : 3.198e-03
: 159 : vars : 3.166e-03
: 160 : vars : 3.156e-03
: 161 : vars : 3.150e-03
: 162 : vars : 3.128e-03
: 163 : vars : 3.127e-03
: 164 : vars : 3.114e-03
: 165 : vars : 3.102e-03
: 166 : vars : 3.086e-03
: 167 : vars : 3.078e-03
: 168 : vars : 3.048e-03
: 169 : vars : 2.998e-03
: 170 : vars : 2.935e-03
: 171 : vars : 2.932e-03
: 172 : vars : 2.911e-03
: 173 : vars : 2.904e-03
: 174 : vars : 2.886e-03
: 175 : vars : 2.825e-03
: 176 : vars : 2.821e-03
: 177 : vars : 2.769e-03
: 178 : vars : 2.760e-03
: 179 : vars : 2.759e-03
: 180 : vars : 2.643e-03
: 181 : vars : 2.639e-03
: 182 : vars : 2.563e-03
: 183 : vars : 2.514e-03
: 184 : vars : 2.405e-03
: 185 : vars : 2.398e-03
: 186 : vars : 2.338e-03
: 187 : vars : 2.331e-03
: 188 : vars : 2.276e-03
: 189 : vars : 2.236e-03
: 190 : vars : 2.203e-03
: 191 : vars : 2.144e-03
: 192 : vars : 2.106e-03
: 193 : vars : 2.091e-03
: 194 : vars : 2.061e-03
: 195 : vars : 2.059e-03
: 196 : vars : 2.034e-03
: 197 : vars : 1.676e-03
: 198 : vars : 1.600e-03
: 199 : vars : 1.572e-03
: 200 : vars : 1.522e-03
: 201 : vars : 1.424e-03
: 202 : vars : 1.253e-03
: 203 : vars : 1.187e-03
: 204 : vars : 1.146e-03
: 205 : vars : 6.807e-04
: 206 : vars : 5.268e-04
: 207 : vars : 4.696e-04
: 208 : vars : 0.000e+00
: 209 : vars : 0.000e+00
: 210 : vars : 0.000e+00
: 211 : vars : 0.000e+00
: 212 : vars : 0.000e+00
: 213 : vars : 0.000e+00
: 214 : vars : 0.000e+00
: 215 : vars : 0.000e+00
: 216 : vars : 0.000e+00
: 217 : vars : 0.000e+00
: 218 : vars : 0.000e+00
: 219 : vars : 0.000e+00
: 220 : vars : 0.000e+00
: 221 : vars : 0.000e+00
: 222 : vars : 0.000e+00
: 223 : vars : 0.000e+00
: 224 : vars : 0.000e+00
: 225 : vars : 0.000e+00
: 226 : vars : 0.000e+00
: 227 : vars : 0.000e+00
: 228 : vars : 0.000e+00
: 229 : vars : 0.000e+00
: 230 : vars : 0.000e+00
: 231 : vars : 0.000e+00
: 232 : vars : 0.000e+00
: 233 : vars : 0.000e+00
: 234 : vars : 0.000e+00
: 235 : vars : 0.000e+00
: 236 : vars : 0.000e+00
: 237 : vars : 0.000e+00
: 238 : vars : 0.000e+00
: 239 : vars : 0.000e+00
: 240 : vars : 0.000e+00
: 241 : vars : 0.000e+00
: 242 : vars : 0.000e+00
: 243 : vars : 0.000e+00
: 244 : vars : 0.000e+00
: 245 : vars : 0.000e+00
: 246 : vars : 0.000e+00
: 247 : vars : 0.000e+00
: 248 : vars : 0.000e+00
: 249 : vars : 0.000e+00
: 250 : vars : 0.000e+00
: 251 : vars : 0.000e+00
: 252 : vars : 0.000e+00
: 253 : vars : 0.000e+00
: 254 : vars : 0.000e+00
: 255 : vars : 0.000e+00
: 256 : vars : 0.000e+00
: --------------------------------------
: No variable ranking supplied by classifier: TMVA_DNN_CPU
: No variable ranking supplied by classifier: TMVA_CNN_CPU
TH1.Print Name = TrainingHistory_TMVA_DNN_CPU_trainingError, Entries= 0, Total sum= 4.96886
TH1.Print Name = TrainingHistory_TMVA_DNN_CPU_valError, Entries= 0, Total sum= 12.6622
TH1.Print Name = TrainingHistory_TMVA_CNN_CPU_trainingError, Entries= 0, Total sum= 8.73329
TH1.Print Name = TrainingHistory_TMVA_CNN_CPU_valError, Entries= 0, Total sum= 7.7916
Factory : === Destroy and recreate all methods via weight files for testing ===
:
: Reading weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_BDT.weights.xml␛[0m
: Reading weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_DNN_CPU.weights.xml␛[0m
: Reading weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_CNN_CPU.weights.xml␛[0m
Factory : ␛[1mTest all methods␛[0m
Factory : Test method: BDT for Classification performance
:
BDT : [dataset] : Evaluation of BDT on testing sample (400 events)
: Elapsed time for evaluation of 400 events: 0.00174 sec
Factory : Test method: TMVA_DNN_CPU for Classification performance
:
: Evaluate deep neural network on CPU using batches with size = 400
:
TMVA_DNN_CPU : [dataset] : Evaluation of TMVA_DNN_CPU on testing sample (400 events)
: Elapsed time for evaluation of 400 events: 0.0125 sec
Factory : Test method: TMVA_CNN_CPU for Classification performance
:
: Evaluate deep neural network on CPU using batches with size = 400
:
TMVA_CNN_CPU : [dataset] : Evaluation of TMVA_CNN_CPU on testing sample (400 events)
: Elapsed time for evaluation of 400 events: 0.0881 sec
Factory : ␛[1mEvaluate all methods␛[0m
Factory : Evaluate classifier: BDT
:
BDT : [dataset] : Loop over test events and fill histograms with classifier response...
:
: Dataset[dataset] : variable plots are not produces ! The number of variables is 256 , it is larger than 200
Factory : Evaluate classifier: TMVA_DNN_CPU
:
TMVA_DNN_CPU : [dataset] : Loop over test events and fill histograms with classifier response...
:
: Evaluate deep neural network on CPU using batches with size = 1000
:
: Dataset[dataset] : variable plots are not produces ! The number of variables is 256 , it is larger than 200
Factory : Evaluate classifier: TMVA_CNN_CPU
:
TMVA_CNN_CPU : [dataset] : Loop over test events and fill histograms with classifier response...
:
: Evaluate deep neural network on CPU using batches with size = 1000
:
: Dataset[dataset] : variable plots are not produces ! The number of variables is 256 , it is larger than 200
:
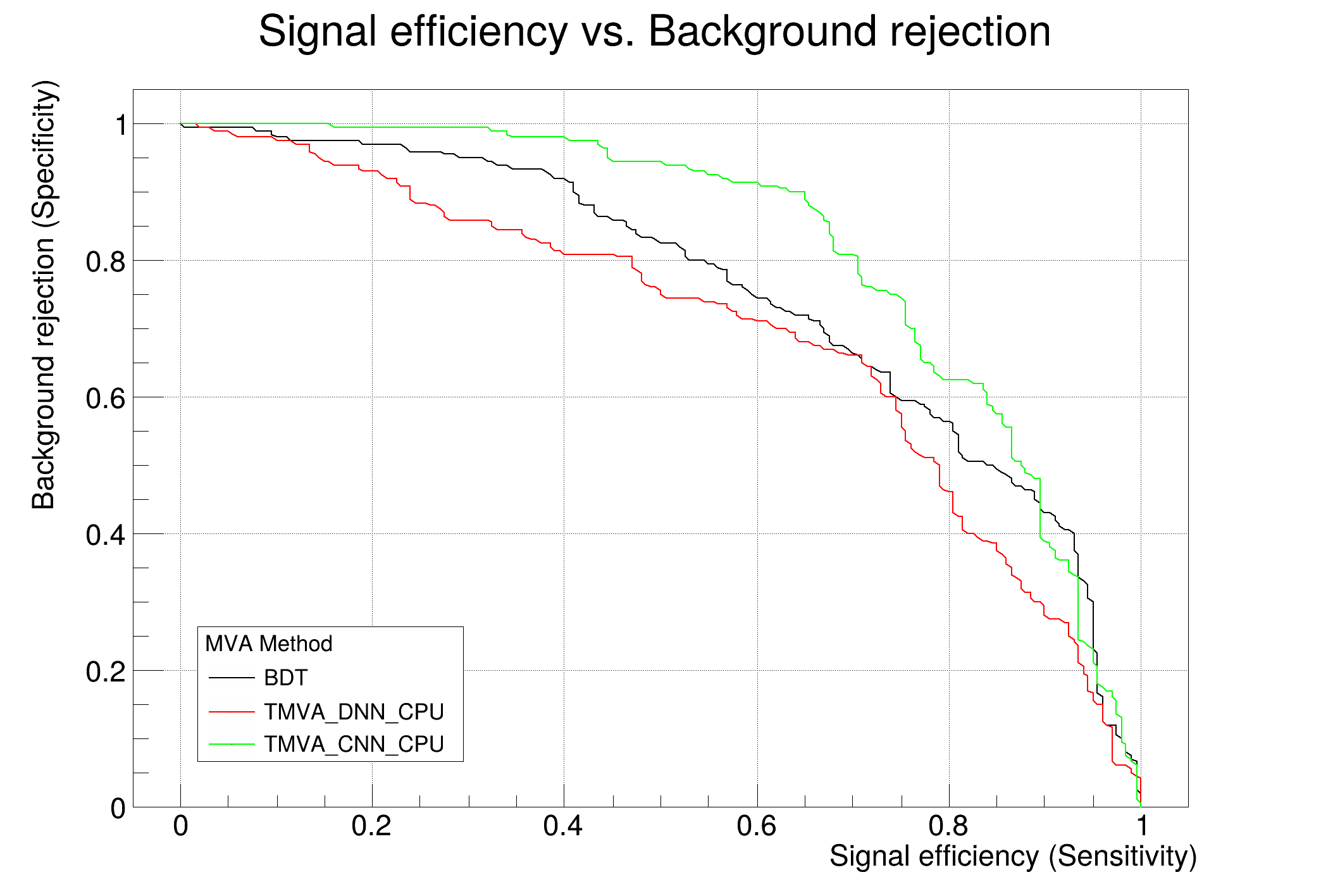
: Evaluation results ranked by best signal efficiency and purity (area)
: -------------------------------------------------------------------------------------------------------------------
: DataSet MVA
: Name: Method: ROC-integ
: dataset BDT : 0.687
: dataset TMVA_CNN_CPU : 0.669
: dataset TMVA_DNN_CPU : 0.625
: -------------------------------------------------------------------------------------------------------------------
:
: Testing efficiency compared to training efficiency (overtraining check)
: -------------------------------------------------------------------------------------------------------------------
: DataSet MVA Signal efficiency: from test sample (from training sample)
: Name: Method: @B=0.01 @B=0.10 @B=0.30
: -------------------------------------------------------------------------------------------------------------------
: dataset BDT : 0.085 (0.285) 0.315 (0.595) 0.577 (0.798)
: dataset TMVA_CNN_CPU : 0.012 (0.055) 0.205 (0.349) 0.553 (0.603)
: dataset TMVA_DNN_CPU : 0.017 (0.112) 0.145 (0.510) 0.450 (0.745)
: -------------------------------------------------------------------------------------------------------------------
:
Dataset:dataset : Created tree 'TestTree' with 400 events
:
Dataset:dataset : Created tree 'TrainTree' with 1600 events
:
Factory : ␛[1mThank you for using TMVA!␛[0m
: ␛[1mFor citation information, please visit: http://tmva.sf.net/citeTMVA.html␛[0m