 |
ROOT 6.16/01 Reference Guide |
| |
ROOT 6.16/01 Reference Guide |
ROOT's RDataFrame offers a high level interface for analyses of data stored in TTrees, CSV's and other data formats.
In addition, multi-threading and other low-level optimisations allow users to exploit all the resources available on their machines completely transparently.
Skip to the class reference or keep reading for the user guide.
In a nutshell:
Calculations are expressed in terms of a type-safe functional chain of actions and transformations, RDataFrame takes care of their execution. The implementation automatically puts in place several low level optimisations such as multi-thread parallelisation and caching.
![]()
You can directly see RDataFrame in action through its code examples, both in C++ and Python.
These are the operations which can be performed with RDataFrame
Transformations are a way to manipulated the data.
| Transformation | Description |
|---|---|
| Define | Creates a new column in the dataset. |
| DefineSlot | Same as Define, but the user-defined function must take an extra unsigned int slot as its first parameter. slot will take a different value, 0 to nThreads - 1, for each thread of execution. This is meant as a helper in writing thread-safe Define transformation when using RDataFrame after ROOT::EnableImplicitMT(). DefineSlot works just as well with single-thread execution: in that case slot will always be 0. |
| DefineSlotEntry | Same as DefineSlot, but the entry number is passed in addition to the slot number. This is meant as a helper in case some dependency on the entry number needs to be honoured. |
| Filter | Filter the rows of the dataset. |
| Range | Creates a node that filters entries based on range of entries |
Actions are a way to produce a result out of the data. Each one is described in more detail in the reference guide.
In the following, whenever we say an action "returns" something, we always mean it returns a smart pointer to it. Also note that all actions are only executed for events that pass all preceding filters.
Lazy actions only trigger the event loop when one of the results is accessed for the first time, making it easy to produce several different results in one event loop. Instant actions trigger the event loop instantly.
| Lazy action | Description |
|---|---|
| Aggregate | Execute a user-defined accumulation operation on the processed column values. |
| Book | Book execution of a custom action using a user-defined helper object. |
| Cache | Caches in contiguous memory columns' entries. Custom columns can be cached as well, filtered entries are not cached. Users can specify which columns to save (default is all). |
| Count | Return the number of events processed. |
| Display | Obtains the events in the dataset for the requested columns. The method returns a RDisplay instance which can be queried to get a compressed tabular representation on the standard output or a complete representation as a string. |
| Fill | Fill a user-defined object with the values of the specified branches, as if by calling `Obj.Fill(branch1, branch2, ...). |
| Graph | Fills a TGraph with the two columns provided. If Multithread is enabled, the order of the points may not be the one expected, it is therefore suggested to sort if before drawing. |
| Histo{1D,2D,3D} | Fill a {one,two,three}-dimensional histogram with the processed branch values. |
| Max | Return the maximum of processed branch values. If the type of the column is inferred, the return type is double, the type of the column otherwise. |
| Mean | Return the mean of processed branch values. |
| Min | Return the minimum of processed branch values. If the type of the column is inferred, the return type is double, the type of the column otherwise. |
| Profile{1D,2D} | Fill a {one,two}-dimensional profile with the branch values that passed all filters. |
| Reduce | Reduce (e.g. sum, merge) entries using the function (lambda, functor...) passed as argument. The function must have signature T(T,T) where T is the type of the branch. Return the final result of the reduction operation. An optional parameter allows initialization of the result object to non-default values. |
| Report | Obtains statistics on how many entries have been accepted and rejected by the filters. See the section on named filters for a more detailed explanation. The method returns a RCutFlowReport instance which can be queried programmatically to get information about the effects of the individual cuts. |
| StdDev | Return the unbiased standard deviation of the processed branch values. |
| Sum | Return the sum of the values in the column. If the type of the column is inferred, the return type is double, the type of the column otherwise. |
| Take | Extract a column from the dataset as a collection of values. If the type of the column is a C-style array, the type stored in the return container is a ROOT::VecOps::RVec<T> to guarantee the lifetime of the data involved. |
| Instant action | Description |
|---|---|
| Foreach | Execute a user-defined function on each entry. Users are responsible for the thread-safety of this lambda when executing with implicit multi-threading enabled. |
| ForeachSlot | Same as Foreach, but the user-defined function must take an extra unsigned int slot as its first parameter. slot will take a different value, 0 to nThreads - 1, for each thread of execution. This is meant as a helper in writing thread-safe Foreach actions when using RDataFrame after ROOT::EnableImplicitMT(). ForeachSlot works just as well with single-thread execution: in that case slot will always be 0. |
| Snapshot | Writes processed data-set to disk, in a new TTree and TFile. Custom columns can be saved as well, filtered entries are not saved. Users can specify which columns to save (default is all). Snapshot, by default, overwrites the output file if it already exists. Snapshot can be made lazy setting the appropriate flage in the snapshot options. |
| Operation | Description |
|---|---|
| Alias | Introduce an alias for a particular column name. |
| GetColumnNames | Get the names of all the available columns of the dataset. |
| GetDefinedColumnNames | Get the names of all the defined columns |
| GetColumnType | Return the type of a given column as a string. |
| GetColumnTypeNamesList | Return the list of type names of columns in the dataset. |
| GetFilterNames | Get all the filters defined. If called on a root node, all filters will be returned. For any other node, only the filters upstream of that node. |
| Display | Provides an ASCII representation of the columns types and contents of the dataset printable by the user. |
| SaveGraph | Store the computation graph of an RDataFrame in graphviz format for easy inspection. |
Users define their analysis as a sequence of operations to be performed on the data-frame object; the framework takes care of the management of the loop over entries as well as low-level details such as I/O and parallelisation. RDataFrame provides methods to perform most common operations required by ROOT analyses; at the same time, users can just as easily specify custom code that will be executed in the event loop.
RDataFrame is built with a modular and flexible workflow in mind, summarised as follows:
The following table shows how analyses based on TTreeReader and TTree::Draw translate to RDataFrame. Follow the crash course to discover more idiomatic and flexible ways to express analyses with RDataFrame.
| TTreeReader | ROOT::RDataFrame |
while(reader.Next()) {
}
An interface for reading values stored in ROOT columnar datasets. Definition: TTreeReaderValue.h:132 A simple, robust and fast interface to read values from ROOT colmnar datasets such as TTree,... Definition: TTreeReader.h:44 | d.Filter(IsGoodEvent).Foreach(DoStuff);
|
| TTree::Draw | ROOT::RDataFrame |
TTree *t = nullptr;
file->GetObject("myTree", t);
|
All snippets of code presented in the crash course can be executed in the ROOT interpreter. Simply precede them with
which is omitted for brevity. The terms "column" and "branch" are used interchangeably.
RDataFrame's constructor is where the user specifies the dataset and, optionally, a default set of columns that operations should work with. Here are the most common methods to construct a RDataFrame object:
Additionally, users can construct a RDataFrame specifying just an integer number. This is the number of "events" that will be generated by this RDataFrame.
This is useful to generate simple data-sets on the fly: the contents of each event can be specified via the Define transformation (explained below). For example, we have used this method to generate Pythia events (with a Define transformation) and write them to disk in parallel (with the Snapshot action).
Let's now tackle a very common task, filling a histogram:
The first line creates a RDataFrame associated to the TTree "myTree". This tree has a branch named "MET".
Histo1D is an action; it returns a smart pointer (a RResultPtr to be precise) to a TH1D histogram filled with the MET of all events. If the quantity stored in the branch is a collection (e.g. a vector or an array), the histogram is filled with its elements.
You can use the objects returned by actions as if they were pointers to the desired results. There are many other possible actions, and all their results are wrapped in smart pointers; we'll see why in a minute.
Let's say we want to cut over the value of branch "MET" and count how many events pass this cut. This is one way to do it:
The filter string (which must contain a valid c++ expression) is applied to the specified branches for each event; the name and types of the columns are inferred automatically. The string expression is required to return a bool which signals whether the event passes the filter (true) or not (false).
You can think of your data as "flowing" through the chain of calls, being transformed, filtered and finally used to perform actions. Multiple Filter calls can be chained one after another.
Using string filters is nice for simple things, but they are limited to specifying the equivalent of a single return statement or the body of a lambda, so it's cumbersome to use strings with more complex filters. They also add a small runtime overhead, as ROOT needs to just-in-time compile the string into C++ code. When more freedom is required or runtime performance is very important, a C++ callable can be specified instead (a lambda in the following snippet, but it can be any kind of function or even a functor class), together with a list of branch names. This snippet is analogous to the one above:
An example of a more complex filter expressed as a string containing C++ code is shown below
The code snippet above defines a column p that is a fixed-size array using the component column names and then filters on its magnitude by looping over its elements. It must be noted that the usage of strings to define columns like the one above is a major advantage when using PyROOT. However, only constants and data coming from other columns in the dataset can be involved in the code passed as a string. Local variables and functions cannot be used, since the interpreter will not know how to find them. When capturing local state is necessary, a C++ callable can be used.
More information on filters and how to use them to automatically generate cutflow reports can be found below.
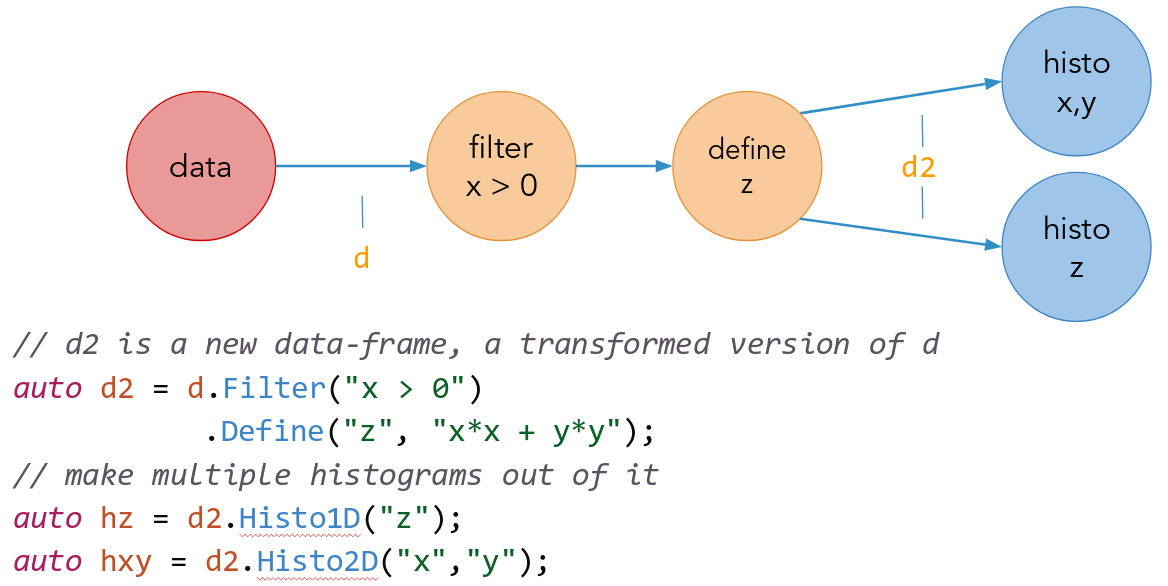
Let's now consider the case in which "myTree" contains two quantities "x" and "y", but our analysis relies on a derived quantity z = sqrt(x*x + y*y). Using the Define transformation, we can create a new column in the data-set containing the variable "z":
Define creates the variable "z" by applying sqrtSum to "x" and "y". Later in the chain of calls we refer to variables created with Define as if they were actual tree branches/columns, but they are evaluated on demand, at most once per event. As with filters, Define calls can be chained with other transformations to create multiple custom columns. Define and Filter transformations can be concatenated and intermixed at will.
As with filters, it is possible to specify new columns as string expressions. This snippet is analogous to the one above:
Again the names of the branches used in the expression and their types are inferred automatically. The string must be valid c++ and is just-in-time compiled by the ROOT interpreter, cling – the process has a small runtime overhead.
Previously, when showing the different ways a RDataFrame can be created, we showed a constructor that only takes a number of entries a parameter. In the following example we show how to combine such an "empty" RDataFrame with Define transformations to create a data-set on the fly. We then save the generated data on disk using the Snapshot action.
This example is slightly more advanced than what we have seen so far: for starters, it makes use of lambda captures (a simple way to make external variables available inside the body of c++ lambdas) to act on the same variable x from both Define transformations. Secondly we have stored the transformed data-frame in a variable. This is always possible: at each point of the transformation chain, users can store the status of the data-frame for further use (more on this below).
You can read more about defining new columns here.
It is sometimes necessary to limit the processing of the dataset to a range of entries. For this reason, the RDataFrame offers the concept of ranges as a node of the RDataFrame chain of transformations; this means that filters, columns and actions can be concatenated to and intermixed with Ranges. If a range is specified after a filter, the range will act exclusively on the entries passing the filter – it will not even count the other entries! The same goes for a Range hanging from another Range. Here are some commented examples:
Note that ranges are not available when multi-threading is enabled. More information on ranges is available here.
As a final example let us apply two different cuts on branch "MET" and fill two different histograms with the "pt\_v" of the filtered events. By now, you should be able to easily understand what's happening:
RDataFrame executes all above actions by running the event-loop only once. The trick is that actions are not executed at the moment they are called, but they are lazy, i.e. delayed until the moment one of their results is accessed through the smart pointer. At that time, the event loop is triggered and all results are produced simultaneously.
It is therefore good practice to declare all your transformations and actions before accessing their results, allowing RDataFrame to run the loop once and produce all results in one go.
Let's say we would like to run the previous examples in parallel on several cores, dividing events fairly between cores. The only modification required to the snippets would be the addition of this line before constructing the main data-frame object:
Simple as that. More details are given below.
Here is a list of the most important features that have been omitted in the "Crash course" for brevity. You don't need to read all these to start using RDataFrame, but they are useful to save typing time and runtime.
The GetColumnsNames() method returns the list of valid column names for the dataset:
When using RDataFrame to read data from a ROOT file, users can specify that the type of a branch is RVec<T> to indicate the branch is a c-style array, a std::vector or any other collection type associated to a contiguous storage in memory.
Column values of type RVec<T> perform no copy of the underlying array data and offer a rich interface to operate on the array elements in a vectorised fashion.
The RVec<T> type signals to RDataFrame that a special behaviour needs to be adopted when snapshotting a dataset on disk. Indeed, if columns which are variable size C arrays are treated via the RVec<T>, RDataFrame will correctly persistify them - if anything else is adopted, for example std::span, only the first element of the array will be written.
Learn more on RVec.
It's possible to schedule execution of arbitrary functions (callbacks) during the event loop. Callbacks can be used e.g. to inspect partial results of the analysis while the event loop is running, drawing a partially-filled histogram every time a certain number of new entries is processed, or event displaying a progress bar while the event loop runs.
For example one can draw an up-to-date version of a result histogram every 100 entries like this:
Callbacks are registered to a RResultPtr and must be callables that takes a reference to the result type as argument and return nothing. RDataFrame will invoke registered callbacks passing partial action results as arguments to them (e.g. a histogram filled with a part of the selected events).
Read more on RResultPtr::OnPartialResult().
When constructing a RDataFrame object, it is possible to specify a default column list for your analysis, in the usual form of a list of strings representing branch/column names. The default column list will be used as a fallback whenever a list specific to the transformation/action is not present. RDataFrame will take as many of these columns as needed, ignoring trailing extra names if present.
Every instance of RDataFrame is created with two special columns called rdfentry_ and rdfslot_. The rdfentry_ column is an unsigned 64-bit integer holding the current entry number while rdfslot_ is an unsigned 32-bit integer holding the index of the current data processing slot. For backwards compatibility reasons, the names tdfentry_ and tdfslot_ are also accepted. These columns are not considered by operations such as Cache or Snapshot. The cached or snapshot data frame provides "its own" values for these columns which do not necessarily correspond to the ones of the mother data frame. This is most notably the case where filters are used before deriving a cached/persistified dataframe.
Note that in multi-thread event loops the values of rdfentry_ do not correspond to what would be the entry numbers of a TChain constructed over the same set of ROOT files, as the entries are processed in an unspecified order.
C++ is a statically typed language: all types must be known at compile-time. This includes the types of the TTree branches we want to work on. For filters, temporary columns and some of the actions, branch types are deduced from the signature of the relevant filter function/temporary column expression/action function:
If we specify an incorrect type for one of the branches, an exception with an informative message will be thrown at runtime, when the branch value is actually read from the TTree: RDataFrame detects type mismatches. The same would happen if we swapped the order of "b1" and "b2" in the branch list passed to Filter.
Certain actions, on the other hand, do not take a function as argument (e.g. Histo1D), so we cannot deduce the type of the branch at compile-time. In this case **RDataFrame infers the type of the branch** from the TTree itself. This is why we never needed to specify the branch types for all actions in the above snippets.
When the branch type is not a common one such as int, double, char or float it is nonetheless good practice to specify it as a template parameter to the action itself, like this:
Deducing types at runtime requires the just-in-time compilation of the relevant actions, which has a small runtime overhead, so specifying the type of the columns as template parameters to the action is good practice when performance is a goal.
RDataFrame strives to offer a comprehensive set of standard actions that can be performed on each event. At the same time, it allows users to execute arbitrary code (i.e. a generic action) inside the event loop through the Foreach and ForeachSlot actions.
Foreach(f, columnList) takes a function f (lambda expression, free function, functor...) and a list of columns, and executes f on those columns for each event. The function passed must return nothing (i.e. void). It can be used to perform actions that are not already available in the interface. For example, the following snippet evaluates the root mean square of column "b":
When executing on multiple threads, users are responsible for the thread-safety of the expression passed to Foreach: each thread will execute the expression multiple times (once per entry) in an unspecified order. The code above would need to employ some resource protection mechanism to ensure non-concurrent writing of rms; but this is probably too much head-scratch for such a simple operation.
ForeachSlot can help in this situation. It is an alternative version of Foreach for which the function takes an additional parameter besides the columns it should be applied to: an unsigned int slot parameter, where slot is a number indicating which thread (0, 1, 2 , ..., poolSize - 1) the function is being run in. More specifically, RDataFrame guarantees that ForeachSlot will invoke the user expression with different slot parameters for different concurrent executions (there is no guarantee that a certain slot number will always correspond to a given thread id, though). We can take advantage of ForeachSlot to evaluate a thread-safe root mean square of branch "b":
You see how we created one double variable for each thread in the pool, and later merged their results via std::accumulate.
Friend trees are supported by RDataFrame. In order to deal with friend trees with RDataFrame, the user is required to build the tree and its friends and instantiate a RDataFrame with it.
RDataFrame can be interfaced with RDataSources. The RDataSource interface defines an API that RDataFrame can use to read arbitrary data formats.
A concrete RDataSource implementation (i.e. a class that inherits from RDataSource and implements all of its pure methods) provides an adaptor that RDataFrame can leverage to read any kind of tabular data formats. RDataFrame calls into RDataSource to retrieve information about the data, retrieve (thread-local) readers or "cursors" for selected columns and to advance the readers to the desired data entry. Some predefined RDataSources are natively provided by ROOT such as the RCsvDS which allows to read comma separated files:
Sets of transformations can be stored as variables** and reused multiple times to create call graphs in which several paths of filtering/creation of columns are executed simultaneously; we often refer to this as "storing the state of the chain".
This feature can be used, for example, to create a temporary column once and use it in several subsequent filters or actions, or to apply a strict filter to the data-set before executing several other transformations and actions, effectively reducing the amount of events processed.
Let's try to make this clearer with a commented example:
RDataFrame detects when several actions use the same filter or the same temporary column, and only evaluates each filter or temporary column once per event, regardless of how many times that result is used down the call graph. Objects read from each column are built once and never copied, for maximum efficiency. When "upstream" filters are not passed, subsequent filters, temporary column expressions and actions are not evaluated, so it might be advisable to put the strictest filters first in the chain.
It is possible to print the computation graph from any node to obtain a dot representation either on the standard output or in a file.
Invoking the function ROOT::RDF::SaveGraph() on any node that is not the head node, the computation graph of the branch the node belongs to is printed. By using the head node, the entire computation graph is printed.
Following there is an example of usage:
RDataFrame variables/nodes are relatively cheap to copy and it's possible to both pass them to (or move them into) functions and to return them from functions. However, in general each dataframe node will have a different C++ type, which includes all available compile-time information about what that node does. One way to cope with this complication is to use template functions and/or C++14 auto return types:
A possibly simpler, C++11-compatible alternative is to take advantage of the fact that any dataframe node can be converted to the common type ROOT::RDF::RNode:
The conversion to ROOT::RDF::RNode is cheap, but it will introduce an extra virtual call during the RDataFrame event loop (in most cases, the resulting performance impact should be negligible).
As a final note, remember that RDataFrame actions do not return another dataframe, but a RResultPtr<T>, where T is the type of the result of the action.
Read more on this topic here.
A filter is defined through a call to Filter(f, columnList). f can be a function, a lambda expression, a functor class, or any other callable object. It must return a bool signalling whether the event has passed the selection (true) or not (false). It must perform "read-only" actions on the columns, and should not have side-effects (e.g. modification of an external or static variable) to ensure correct results when implicit multi-threading is active.
RDataFrame only evaluates filters when necessary: if multiple filters are chained one after another, they are executed in order and the first one returning false causes the event to be discarded and triggers the processing of the next entry. If multiple actions or transformations depend on the same filter, that filter is not executed multiple times for each entry: after the first access it simply serves a cached result.
An optional string parameter name can be passed to the Filter method to create a named filter. Named filters work as usual, but also keep track of how many entries they accept and reject.
Statistics are retrieved through a call to the Report method:
Report is called on the main RDataFrame object, it returns a RResultPtr<RCutFlowReport> relative to all named filters declared up to that pointDefine or Filter), it returns a RResultPtr<RCutFlowReport> relative all named filters in the section of the chain between the main RDataFrame and that node (included).Stats are stored in the same order as named filters have been added to the graph, and refer to the latest event-loop that has been run using the relevant RDataFrame.
When RDataFrame is not being used in a multi-thread environment (i.e. no call to EnableImplicitMT was made), Range transformations are available. These act very much like filters but instead of basing their decision on a filter expression, they rely on begin,end and stride parameters.
begin: initial entry number considered for this range.end: final entry number (excluded) considered for this range. 0 means that the range goes until the end of the dataset.stride: process one entry of the [begin, end) range every stride entries. Must be strictly greater than 0.The actual number of entries processed downstream of a Range node will be (end - begin)/stride (or less if less entries than that are available).
Note that ranges act "locally", not based on the global entry count: Range(10,50) means "skip the first 10 entries
that reach this node*, let the next 40 entries pass, then stop processing". If a range node hangs from a filter node, and the range has a begin parameter of 10, that means the range will skip the first 10 entries that pass the preceding filter.
Ranges allow "early quitting": if all branches of execution of a functional graph reached their end value of processed entries, the event-loop is immediately interrupted. This is useful for debugging and quick data explorations.
Custom columns are created by invoking Define(name, f, columnList). As usual, f can be any callable object (function, lambda expression, functor class...); it takes the values of the columns listed in columnList (a list of strings) as parameters, in the same order as they are listed in columnList. f must return the value that will be assigned to the temporary column.
A new variable is created called name, accessible as if it was contained in the dataset from subsequent transformations/actions.
Use cases include:
An exception is thrown if the name of the new column/branch is already in use for another branch in the TTree.
It is also possible to specify the quantity to be stored in the new temporary column as a C++ expression with the method Define(name, expression). For example this invocation
will create a new column called "pt" the value of which is calculated starting from the columns px and py. The system builds a just-in-time compiled function starting from the expression after having deduced the list of necessary branches from the names of the variables specified by the user.
It is possible to create custom columns also as a function of the processing slot and entry numbers. The methods that can be invoked are:
DefineSlot(name, f, columnList). In this case the callable f has this signature R(unsigned int, T1, T2, ...): the first parameter is the slot number which ranges from 0 to ROOT::GetImplicitMTPoolSize() - 1.DefineSlotEntry(name, f, columnList). In this case the callable f has this signature R(unsigned int, ULong64_t, T1, T2, ...): the first parameter is the slot number while the second one the number of the entry being processed.Actions can be instant or lazy. Instant actions are executed as soon as they are called, while lazy actions are executed whenever the object they return is accessed for the first time. As a rule of thumb, actions with a return value are lazy, the others are instant.
As pointed out before in this document, RDataFrame can transparently perform multi-threaded event loops to speed up the execution of its actions. Users have to call ROOT::EnableImplicitMT() before constructing the RDataFrame object to indicate that it should take advantage of a pool of worker threads. Each worker thread processes a distinct subset of entries, and their partial results are merged before returning the final values to the user. More specifically, the dataset will be divided in batches of entries, and threads will divide among themselves the processing of these batches. There are no guarantees on the order the batches are processed, i.e. no guarantees in the order entries of the dataset are processed. Note that this in turn means that, for multi-thread event loops, there is no guarantee on the order in which Snapshot will write entries: they could be scrambled with respect to the input dataset.
RDataFrame operations such as Histo1D or Snapshot are guaranteed to work correctly in multi-thread event loops. User-defined expressions, such as strings or lambdas passed to Filter, Define, Foreach, Reduce or Aggregate will have to be thread-safe, i.e. it should be possible to call them concurrently from different threads.
Note that simple Filter and Define transformations will inherently satisfy this requirement: Filter/Define expressions will often be pure in the functional programming sense (no side-effects, no dependency on external state), which eliminates all risks of race conditions.
In order to facilitate writing of thread-safe operations, some RDataFrame features such as Foreach, Define or OnPartialResult offer thread-aware counterparts (ForeachSlot, DefineSlot, OnPartialResultSlot): their only difference is that they will pass an extra slot argument (an unsigned integer) to the user-defined expression. When calling user-defined code concurrently, RDataFrame guarantees that different threads will employ different values of the slot parameter, where slot will be a number between 0 and ROOT::GetImplicitMTPoolSize() - 1. In other words, within a slot, computation runs sequentially and events are processed sequentially. Note that the same slot might be associated to different threads over the course of a single event loop, but two threads will never receive the same slot at the same time. This extra parameter might facilitate writing safe parallel code by having each thread write/modify a different processing slot*, e.g. a different element of a list. See here for an example usage of ForeachSlot.
Definition at line 41 of file RDataFrame.hxx.
Public Types | |
| using | ColumnNames_t = RDFDetail::ColumnNames_t |
Public Member Functions | |
| RDataFrame (std::string_view treeName, ::TDirectory *dirPtr, const ColumnNames_t &defaultBranches={}) | |
| RDataFrame (std::string_view treename, const std::vector< std::string > &filenames, const ColumnNames_t &defaultBranches={}) | |
| Build the dataframe. More... | |
| RDataFrame (std::string_view treeName, std::string_view filenameglob, const ColumnNames_t &defaultBranches={}) | |
| Build the dataframe. More... | |
| RDataFrame (std::unique_ptr< ROOT::RDF::RDataSource >, const ColumnNames_t &defaultBranches={}) | |
| Build dataframe associated to datasource. More... | |
| RDataFrame (TTree &tree, const ColumnNames_t &defaultBranches={}) | |
| Build the dataframe. More... | |
| RDataFrame (ULong64_t numEntries) | |
| Build a dataframe that generates numEntries entries. More... | |
 Public Member Functions inherited from ROOT::RDF::RInterface< RDFDetail::RLoopManager > Public Member Functions inherited from ROOT::RDF::RInterface< RDFDetail::RLoopManager > | |
| RInterface (const RInterface &)=default | |
| Copy-ctor for RInterface. More... | |
| RInterface (const std::shared_ptr< RDFDetail::RLoopManager > &proxied) | |
| Only enabled when building a RInterface<RLoopManager> More... | |
| RInterface (RInterface &&)=default | |
| Move-ctor for RInterface. More... | |
| RResultPtr< U > | Aggregate (AccFun aggregator, MergeFun merger, std::string_view columnName, const U &aggIdentity) |
| Execute a user-defined accumulation operation on the processed column values in each processing slot. More... | |
| RResultPtr< U > | Aggregate (AccFun aggregator, MergeFun merger, std::string_view columnName="") |
| Execute a user-defined accumulation operation on the processed column values in each processing slot. More... | |
| RInterface< RDFDetail::RLoopManager, DS_t > | Alias (std::string_view alias, std::string_view columnName) |
| Allow to refer to a column with a different name. More... | |
| RResultPtr< typename Helper::Result_t > | Book (Helper &&helper, const ColumnNames_t &columns={}) |
| Book execution of a custom action using a user-defined helper object. More... | |
| RInterface< RLoopManager > | Cache (const ColumnNames_t &columnList) |
| Save selected columns in memory. More... | |
| RInterface< RLoopManager > | Cache (const ColumnNames_t &columnList) |
| Save selected columns in memory. More... | |
| RInterface< RLoopManager > | Cache (std::initializer_list< std::string > columnList) |
| Save selected columns in memory. More... | |
| RInterface< RLoopManager > | Cache (std::string_view columnNameRegexp="") |
| Save selected columns in memory. More... | |
| RResultPtr< ULong64_t > | Count () |
| Return the number of entries processed (lazy action) More... | |
| RInterface< RDFDetail::RLoopManager, DS_t > | Define (std::string_view name, F expression, const ColumnNames_t &columns={}) |
| Creates a custom column. More... | |
| RInterface< RDFDetail::RLoopManager, DS_t > | Define (std::string_view name, std::string_view expression) |
| Creates a custom column. More... | |
| RInterface< RDFDetail::RLoopManager, DS_t > | DefineSlot (std::string_view name, F expression, const ColumnNames_t &columns={}) |
| Creates a custom column with a value dependent on the processing slot. More... | |
| RInterface< RDFDetail::RLoopManager, DS_t > | DefineSlotEntry (std::string_view name, F expression, const ColumnNames_t &columns={}) |
| Creates a custom column with a value dependent on the processing slot and the current entry. More... | |
| RResultPtr< RDisplay > | Display (const ColumnNames_t &columnList, const int &nRows=5) |
| Provides a representation of the columns in the dataset. More... | |
| RResultPtr< RDisplay > | Display (const ColumnNames_t &columnList, const int &nRows=5) |
| Provides a representation of the columns in the dataset. More... | |
| RResultPtr< RDisplay > | Display (std::initializer_list< std::string > columnList, const int &nRows=5) |
| Provides a representation of the columns in the dataset. More... | |
| RResultPtr< RDisplay > | Display (std::string_view columnNameRegexp="", const int &nRows=5) |
| Provides a representation of the columns in the dataset. More... | |
| RResultPtr< T > | Fill (T &&model, const ColumnNames_t &bl) |
Return an object of type T on which T::Fill will be called once per event (lazy action) More... | |
| RResultPtr< T > | Fill (T &&model, const ColumnNames_t &columnList) |
Return an object of type T on which T::Fill will be called once per event (lazy action) More... | |
| RInterface< RDFDetail::RFilter< F, RDFDetail::RLoopManager >, DS_t > | Filter (F f, const ColumnNames_t &columns={}, std::string_view name="") |
| RInterface< RDFDetail::RFilter< F, RDFDetail::RLoopManager >, DS_t > | Filter (F f, const std::initializer_list< std::string > &columns) |
| Append a filter to the call graph. More... | |
| RInterface< RDFDetail::RFilter< F, RDFDetail::RLoopManager >, DS_t > | Filter (F f, std::string_view name) |
| Append a filter to the call graph. More... | |
| RInterface< RDFDetail::RJittedFilter, DS_t > | Filter (std::string_view expression, std::string_view name="") |
| Append a filter to the call graph. More... | |
| void | Foreach (F f, const ColumnNames_t &columns={}) |
| Execute a user-defined function on each entry (instant action) More... | |
| void | ForeachSlot (F f, const ColumnNames_t &columns={}) |
| Execute a user-defined function requiring a processing slot index on each entry (instant action) More... | |
| ColumnNames_t | GetColumnNames () |
| Returns the names of the available columns. More... | |
| std::string | GetColumnType (std::string_view column) |
| Return the type of a given column as a string. More... | |
| ColumnNames_t | GetDefinedColumnNames () |
| Returns the names of the defined columns. More... | |
| std::vector< std::string > | GetFilterNames () |
| Returns the names of the filters created. More... | |
| RResultPtr<::TGraph > | Graph (std::string_view v1Name="", std::string_view v2Name="") |
| Fill and return a graph (lazy action) More... | |
| RResultPtr<::TH1D > | Histo1D (const TH1DModel &model, std::string_view vName, std::string_view wName) |
| Fill and return a one-dimensional histogram with the weighted values of a column (lazy action) More... | |
| RResultPtr<::TH1D > | Histo1D (const TH1DModel &model={"", "", 128u, 0., 0.}) |
| Fill and return a one-dimensional histogram with the weighted values of a column (lazy action) More... | |
| RResultPtr<::TH1D > | Histo1D (const TH1DModel &model={"", "", 128u, 0., 0.}, std::string_view vName="") |
| Fill and return a one-dimensional histogram with the values of a column (lazy action) More... | |
| RResultPtr<::TH1D > | Histo1D (std::string_view vName) |
| Fill and return a one-dimensional histogram with the values of a column (lazy action) More... | |
| RResultPtr<::TH1D > | Histo1D (std::string_view vName, std::string_view wName) |
| Fill and return a one-dimensional histogram with the weighted values of a column (lazy action) More... | |
| RResultPtr<::TH2D > | Histo2D (const TH2DModel &model) |
| RResultPtr<::TH2D > | Histo2D (const TH2DModel &model, std::string_view v1Name, std::string_view v2Name, std::string_view wName) |
| Fill and return a weighted two-dimensional histogram (lazy action) More... | |
| RResultPtr<::TH2D > | Histo2D (const TH2DModel &model, std::string_view v1Name="", std::string_view v2Name="") |
| Fill and return a two-dimensional histogram (lazy action) More... | |
| RResultPtr<::TH3D > | Histo3D (const TH3DModel &model) |
| RResultPtr<::TH3D > | Histo3D (const TH3DModel &model, std::string_view v1Name, std::string_view v2Name, std::string_view v3Name, std::string_view wName) |
| Fill and return a three-dimensional histogram (lazy action) More... | |
| RResultPtr<::TH3D > | Histo3D (const TH3DModel &model, std::string_view v1Name="", std::string_view v2Name="", std::string_view v3Name="") |
| Fill and return a three-dimensional histogram (lazy action) More... | |
| RResultPtr< RDFDetail::MaxReturnType_t< T > > | Max (std::string_view columnName="") |
| Return the maximum of processed column values (lazy action) More... | |
| RResultPtr< double > | Mean (std::string_view columnName="") |
| Return the mean of processed column values (lazy action) More... | |
| RResultPtr< RDFDetail::MinReturnType_t< T > > | Min (std::string_view columnName="") |
| Return the minimum of processed column values (lazy action) More... | |
| operator RNode () const | |
| Cast any RDataFrame node to a common type ROOT::RDF::RNode. More... | |
| RInterface & | operator= (const RInterface &)=default |
| Copy-assignment operator for RInterface. More... | |
| RResultPtr<::TProfile > | Profile1D (const TProfile1DModel &model) |
| RResultPtr<::TProfile > | Profile1D (const TProfile1DModel &model, std::string_view v1Name, std::string_view v2Name, std::string_view wName) |
| Fill and return a one-dimensional profile (lazy action) More... | |
| RResultPtr<::TProfile > | Profile1D (const TProfile1DModel &model, std::string_view v1Name="", std::string_view v2Name="") |
| Fill and return a one-dimensional profile (lazy action) More... | |
| RResultPtr<::TProfile2D > | Profile2D (const TProfile2DModel &model) |
| RResultPtr<::TProfile2D > | Profile2D (const TProfile2DModel &model, std::string_view v1Name, std::string_view v2Name, std::string_view v3Name, std::string_view wName) |
| Fill and return a two-dimensional profile (lazy action) More... | |
| RResultPtr<::TProfile2D > | Profile2D (const TProfile2DModel &model, std::string_view v1Name="", std::string_view v2Name="", std::string_view v3Name="") |
| Fill and return a two-dimensional profile (lazy action) More... | |
| RInterface< RDFDetail::RRange< RDFDetail::RLoopManager >, DS_t > | Range (unsigned int begin, unsigned int end, unsigned int stride=1) |
| Creates a node that filters entries based on range: [begin, end) More... | |
| RInterface< RDFDetail::RRange< RDFDetail::RLoopManager >, DS_t > | Range (unsigned int end) |
| Creates a node that filters entries based on range. More... | |
| RResultPtr< T > | Reduce (F f, std::string_view columnName, const T &redIdentity) |
| Execute a user-defined reduce operation on the values of a column. More... | |
| RResultPtr< T > | Reduce (F f, std::string_view columnName="") |
| Execute a user-defined reduce operation on the values of a column. More... | |
| RResultPtr< RCutFlowReport > | Report () |
| Gather filtering statistics. More... | |
| RResultPtr< RInterface< RLoopManager > > | Snapshot (std::string_view treename, std::string_view filename, const ColumnNames_t &columnList, const RSnapshotOptions &options=RSnapshotOptions()) |
Save selected columns to disk, in a new TTree treename in file filename. More... | |
| RResultPtr< RInterface< RLoopManager > > | Snapshot (std::string_view treename, std::string_view filename, const ColumnNames_t &columnList, const RSnapshotOptions &options=RSnapshotOptions()) |
Save selected columns to disk, in a new TTree treename in file filename. More... | |
| RResultPtr< RInterface< RLoopManager > > | Snapshot (std::string_view treename, std::string_view filename, std::initializer_list< std::string > columnList, const RSnapshotOptions &options=RSnapshotOptions()) |
Save selected columns to disk, in a new TTree treename in file filename. More... | |
| RResultPtr< RInterface< RLoopManager > > | Snapshot (std::string_view treename, std::string_view filename, std::string_view columnNameRegexp="", const RSnapshotOptions &options=RSnapshotOptions()) |
Save selected columns to disk, in a new TTree treename in file filename. More... | |
| RResultPtr< double > | StdDev (std::string_view columnName="") |
| Return the unbiased standard deviation of processed column values (lazy action) More... | |
| RResultPtr< RDFDetail::SumReturnType_t< T > > | Sum (std::string_view columnName="", const RDFDetail::SumReturnType_t< T > &initValue=RDFDetail::SumReturnType_t< T >{}) |
| Return the sum of processed column values (lazy action) More... | |
| RResultPtr< COLL > | Take (std::string_view column="") |
| Return a collection of values of a column (lazy action, returns a std::vector by default) More... | |
Additional Inherited Members | |
| Protected Member Functions inherited from ROOT::RDF::RInterface< RDFDetail::RLoopManager > | |
| RInterface (const std::shared_ptr< RDFDetail::RLoopManager > &proxied, RLoopManager &lm, RDFInternal::RBookedCustomColumns columns, RDataSource *ds) | |
| RDFInternal::RBookedCustomColumns | CheckAndFillDSColumns (ColumnNames_t validCols, std::index_sequence< S... >, TTraits::TypeList< ColumnTypes... >) |
| RLoopManager * | GetLoopManager () const |
| const std::shared_ptr< RDFDetail::RLoopManager > & | GetProxiedPtr () const |
| ColumnNames_t | GetValidatedColumnNames (const unsigned int nColumns, const ColumnNames_t &columns) |
| Prepare the call to the GetValidatedColumnNames routine, making sure that GetBranchNames, which is expensive in terms of runtime, is called at most once. More... | |
#include <ROOT/RDataFrame.hxx>
| using ROOT::RDataFrame::ColumnNames_t = RDFDetail::ColumnNames_t |
Definition at line 43 of file RDataFrame.hxx.
| ROOT::RDataFrame::RDataFrame | ( | std::string_view | treeName, |
| std::string_view | filenameglob, | ||
| const ColumnNames_t & | defaultBranches = {} |
||
| ) |
Build the dataframe.
| [in] | treeName | Name of the tree contained in the directory |
| [in] | filenameglob | TDirectory where the tree is stored, e.g. a TFile. |
| [in] | defaultBranches | Collection of default branches. |
The filename globbing supports the same type of expressions as TChain::Add(). The default branches are looked at in case no branch is specified in the booking of actions or transformations. See RInterface for the documentation of the methods available.
Definition at line 830 of file RDataFrame.cxx.
| ROOT::RDataFrame::RDataFrame | ( | std::string_view | treeName, |
| const std::vector< std::string > & | fileglobs, | ||
| const ColumnNames_t & | defaultBranches = {} |
||
| ) |
Build the dataframe.
| [in] | treeName | Name of the tree contained in the directory |
| [in] | fileglobs | Collection of file names of filename globs |
| [in] | defaultBranches | Collection of default branches. |
The filename globbing supports the same type of expressions as TChain::Add(). The default branches are looked at in case no branch is specified in the booking of actions or transformations. See RInterface for the documentation of the methods available.
Definition at line 849 of file RDataFrame.cxx.
| ROOT::RDataFrame::RDataFrame | ( | std::string_view | treeName, |
| ::TDirectory * | dirPtr, | ||
| const ColumnNames_t & | defaultBranches = {} |
||
| ) |
| ROOT::RDataFrame::RDataFrame | ( | TTree & | tree, |
| const ColumnNames_t & | defaultBranches = {} |
||
| ) |
Build the dataframe.
| [in] | tree | The tree or chain to be studied. |
| [in] | defaultBranches | Collection of default column names to fall back to when none is specified. |
The default branches are looked at in case no branch is specified in the booking of actions or transformations. See RInterface for the documentation of the methods available.
Definition at line 868 of file RDataFrame.cxx.
| ROOT::RDataFrame::RDataFrame | ( | ULong64_t | numEntries | ) |
Build a dataframe that generates numEntries entries.
| [in] | numEntries | The number of entries to generate. |
An empty-source dataframe constructed with a number of entries will generate those entries on the fly when some action is triggered, and it will do so for all the previously-defined temporary branches. See RInterface for the documentation of the methods available.
Definition at line 881 of file RDataFrame.cxx.
| ROOT::RDataFrame::RDataFrame | ( | std::unique_ptr< ROOT::RDF::RDataSource > | ds, |
| const ColumnNames_t & | defaultBranches = {} |
||
| ) |
Build dataframe associated to datasource.
| [in] | ds | The data-source object. |
| [in] | defaultBranches | Collection of default column names to fall back to when none is specified. |
A dataframe associated to a datasource will query it to access column values. See RInterface for the documentation of the methods available.
Definition at line 894 of file RDataFrame.cxx.

 ROOT 6.16/01 - Reference Guide Generated on Sun Dec 19 2021 22:33:04 (GVA Time) using Doxygen 1.9.3 (234637167bd5d39d32bf51f755d58253441f123a).
ROOT 6.16/01 - Reference Guide Generated on Sun Dec 19 2021 22:33:04 (GVA Time) using Doxygen 1.9.3 (234637167bd5d39d32bf51f755d58253441f123a).