This is an example of using a CNN in TMVA. We do classification using a toy image data set that is generated when running the example macro
void MakeImagesTree(
int n,
int nh,
int nw)
{
const int ntot = nh * nw;
TFile f(fileOutName,
"RECREATE");
const int nRndmEvts = 10000;
double delta_sigma = 0.1;
double pixelNoise = 5;
double sX1 = 3;
double sY1 = 3;
double sX2 = sX1 + delta_sigma;
double sY2 = sY1 - delta_sigma;
TH2D h1(
"h1",
"h1", nh, 0, 10, nw, 0, 10);
TH2D h2(
"h2",
"h2", nh, 0, 10, nw, 0, 10);
TTree sgn(
"sig_tree",
"signal_tree");
TTree bkg(
"bkg_tree",
"background_tree");
std::vector<float>
x1(ntot);
std::vector<float>
x2(ntot);
std::vector<float> *px1 = &
x1;
std::vector<float> *px2 = &
x2;
bkg.Branch("vars", "std::vector<float>", &px1);
sgn.Branch("vars", "std::vector<float>", &px2);
f1.SetParameters(1, 5, sX1, 5, sY1);
f2.SetParameters(1, 5, sX2, 5, sY2);
std::cout << "Filling ROOT tree " << std::endl;
for (
int i = 0; i <
n; ++i) {
if (i % 1000 == 0)
std::cout << "Generating image event ... " << i << std::endl;
h2.Reset();
f2.SetParameter(1,
gRandom->Uniform(3, 7));
f2.SetParameter(3,
gRandom->Uniform(3, 7));
h1.FillRandom(
"f1", nRndmEvts);
h2.FillRandom("f2", nRndmEvts);
for (int k = 0; k < nh; ++k) {
for (
int l = 0;
l < nw; ++
l) {
x1[
m] =
h1.GetBinContent(k + 1,
l + 1) +
gRandom->Gaus(0, pixelNoise);
x2[
m] = h2.GetBinContent(k + 1,
l + 1) +
gRandom->Gaus(0, pixelNoise);
}
}
sgn.Fill();
bkg.Fill();
}
sgn.Write();
bkg.Write();
Info(
"MakeImagesTree",
"Signal and background tree with images data written to the file %s",
f.GetName());
sgn.Print();
bkg.Print();
}
void TMVA_CNN_Classification(int nevts = 1000, std::vector<bool> opt = {1, 1, 1, 1, 1})
{
int imgSize = 16 * 16;
TString inputFileName =
"images_data_16x16.root";
bool fileExist = !
gSystem->AccessPathName(inputFileName);
if (!fileExist) {
MakeImagesTree(nevts, 16, 16);
}
bool useTMVACNN = (opt.size() > 0) ? opt[0] : false;
bool useKerasCNN = (opt.size() > 1) ? opt[1] : false;
bool useTMVADNN = (opt.size() > 2) ? opt[2] : false;
bool useTMVABDT = (opt.size() > 3) ? opt[3] : false;
bool usePyTorchCNN = (opt.size() > 4) ? opt[4] : false;
#ifndef R__HAS_TMVACPU
#ifndef R__HAS_TMVAGPU
"TMVA is not build with GPU or CPU multi-thread support. Cannot use TMVA Deep Learning for CNN");
useTMVACNN = false;
#endif
#endif
bool writeOutputFile = true;
#ifdef R__USE_IMT
int num_threads = 4;
gSystem->Setenv(
"OMP_NUM_THREADS",
"1");
if (num_threads >= 0) {
}
#endif
#ifdef R__HAS_PYMVA
gSystem->Setenv(
"KERAS_BACKEND",
"tensorflow");
#else
useKerasCNN = false;
usePyTorchCNN = false;
#endif
TFile *outputFile =
nullptr;
if (writeOutputFile)
outputFile =
TFile::Open(
"TMVA_CNN_ClassificationOutput.root",
"RECREATE");
"TMVA_CNN_Classification", outputFile,
"!V:ROC:!Silent:Color:AnalysisType=Classification:Transformations=None:!Correlations");
std::unique_ptr<TFile> inputFile{
TFile::Open(inputFileName)};
if (!inputFile) {
Error(
"TMVA_CNN_Classification",
"Error opening input file %s - exit", inputFileName.
Data());
return;
}
auto signalTree = inputFile->Get<
TTree>(
"sig_tree");
auto backgroundTree = inputFile->Get<
TTree>(
"bkg_tree");
if (!signalTree) {
Error(
"TMVA_CNN_Classification",
"Could not find signal tree in file '%s'", inputFileName.
Data());
return;
}
if (!backgroundTree) {
Error(
"TMVA_CNN_Classification",
"Could not find background tree in file '%s'", inputFileName.
Data());
return;
}
loader.AddSignalTree(signalTree, signalWeight);
loader.AddBackgroundTree(backgroundTree, backgroundWeight);
loader.AddVariablesArray("vars", imgSize);
int nTrainSig = 0.8 * nEventsSig;
int nTrainBkg = 0.8 * nEventsBkg;
"nTrain_Signal=%d:nTrain_Background=%d:SplitMode=Random:SplitSeed=100:NormMode=NumEvents:!V:!CalcCorrelations",
nTrainSig, nTrainBkg);
loader.PrepareTrainingAndTestTree(mycuts, mycutb, prepareOptions);
if (useTMVABDT) {
"!V:NTrees=200:MinNodeSize=2.5%:MaxDepth=2:BoostType=AdaBoost:AdaBoostBeta=0.5:"
"UseBaggedBoost:BaggedSampleFraction=0.5:SeparationType=GiniIndex:nCuts=20");
}
if (useTMVADNN) {
"Layout=DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,DENSE|1|LINEAR");
TString trainingString1(
"LearningRate=1e-3,Momentum=0.9,Repetitions=1,"
"ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,"
"MaxEpochs=10,WeightDecay=1e-4,Regularization=None,"
"Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.");
TString trainingStrategyString(
"TrainingStrategy=");
trainingStrategyString += trainingString1;
TString dnnOptions(
"!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=None:"
"WeightInitialization=XAVIER");
dnnOptions.Append(":");
dnnOptions.Append(layoutString);
dnnOptions.Append(":");
dnnOptions.Append(trainingStrategyString);
TString dnnMethodName =
"TMVA_DNN_CPU";
#ifdef R__HAS_TMVAGPU
dnnOptions += ":Architecture=GPU";
dnnMethodName = "TMVA_DNN_GPU";
#elif defined(R__HAS_TMVACPU)
dnnOptions += ":Architecture=CPU";
#endif
}
if (useTMVACNN) {
TString inputLayoutString(
"InputLayout=1|16|16");
TString layoutString(
"Layout=CONV|10|3|3|1|1|1|1|RELU,BNORM,CONV|10|3|3|1|1|1|1|RELU,MAXPOOL|2|2|1|1,"
"RESHAPE|FLAT,DENSE|100|RELU,DENSE|1|LINEAR");
TString trainingString1(
"LearningRate=1e-3,Momentum=0.9,Repetitions=1,"
"ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,"
"MaxEpochs=10,WeightDecay=1e-4,Regularization=None,"
"Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.0");
TString trainingStrategyString(
"TrainingStrategy=");
trainingStrategyString +=
trainingString1;
TString cnnOptions(
"!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=None:"
"WeightInitialization=XAVIER");
cnnOptions.Append(":");
cnnOptions.Append(inputLayoutString);
cnnOptions.Append(":");
cnnOptions.Append(layoutString);
cnnOptions.Append(":");
cnnOptions.Append(trainingStrategyString);
TString cnnMethodName =
"TMVA_CNN_CPU";
#ifdef R__HAS_TMVAGPU
cnnOptions += ":Architecture=GPU";
cnnMethodName = "TMVA_CNN_GPU";
#else
cnnOptions += ":Architecture=CPU";
cnnMethodName = "TMVA_CNN_CPU";
#endif
}
#ifdef R__HAS_PYMVA
TString python_exe = tmva_python_exe.
IsNull() ?
"python" : tmva_python_exe;
if (useKerasCNN) {
Info(
"TMVA_CNN_Classification",
"Building convolutional keras model");
m.AddLine(
"import tensorflow");
m.AddLine(
"from tensorflow.keras.models import Sequential");
m.AddLine(
"from tensorflow.keras.optimizers import Adam");
"from tensorflow.keras.layers import Input, Dense, Dropout, Flatten, Conv2D, MaxPooling2D, Reshape, BatchNormalization");
m.AddLine(
"model = Sequential() ");
m.AddLine(
"model.add(Reshape((16, 16, 1), input_shape = (256, )))");
m.AddLine(
"model.add(Conv2D(10, kernel_size = (3, 3), kernel_initializer = 'glorot_normal',activation = "
"'relu', padding = 'same'))");
m.AddLine(
"model.add(BatchNormalization())");
m.AddLine(
"model.add(Conv2D(10, kernel_size = (3, 3), kernel_initializer = 'glorot_normal',activation = "
"'relu', padding = 'same'))");
m.AddLine(
"model.add(MaxPooling2D(pool_size = (2, 2), strides = (1,1))) ");
m.AddLine(
"model.add(Flatten())");
m.AddLine(
"model.add(Dense(256, activation = 'relu')) ");
m.AddLine(
"model.add(Dense(2, activation = 'sigmoid')) ");
m.AddLine(
"model.compile(loss = 'binary_crossentropy', optimizer = Adam(learning_rate = 0.001), weighted_metrics = ['accuracy'])");
m.AddLine(
"model.save('model_cnn.keras')");
m.AddLine(
"model.summary()");
m.SaveSource(
"make_cnn_model.py");
gSystem->Exec(python_exe +
" make_cnn_model.py");
if (
gSystem->AccessPathName(
"model_cnn.keras")) {
Warning(
"TMVA_CNN_Classification",
"Error creating Keras model file - skip using Keras");
} else {
Info(
"TMVA_CNN_Classification",
"Booking tf.Keras CNN model");
factory.BookMethod(
"H:!V:VarTransform=None:FilenameModel=model_cnn.keras:tf.keras:"
"FilenameTrainedModel=trained_model_cnn.keras:NumEpochs=10:BatchSize=100:");
}
}
if (usePyTorchCNN) {
Info(
"TMVA_CNN_Classification",
"Using Convolutional PyTorch Model");
TString pyTorchFileName =
gROOT->GetTutorialDir() +
TString(
"/machine_learning/PyTorch_Generate_CNN_Model.py");
if (
gSystem->Exec(python_exe +
" -c 'import torch'") ||
gSystem->AccessPathName(pyTorchFileName)) {
Warning(
"TMVA_CNN_Classification",
"PyTorch is not installed or model building file is not existing - skip using PyTorch");
} else {
Info(
"TMVA_CNN_Classification",
"Booking PyTorch CNN model");
TString methodOpt =
"H:!V:VarTransform=None:FilenameModel=PyTorchModelCNN.pt:"
"FilenameTrainedModel=PyTorchTrainedModelCNN.pt:NumEpochs=10:BatchSize=100";
methodOpt +=
TString(
":UserCode=") + pyTorchFileName;
}
}
#endif
factory.TrainAllMethods();
factory.TestAllMethods();
factory.EvaluateAllMethods();
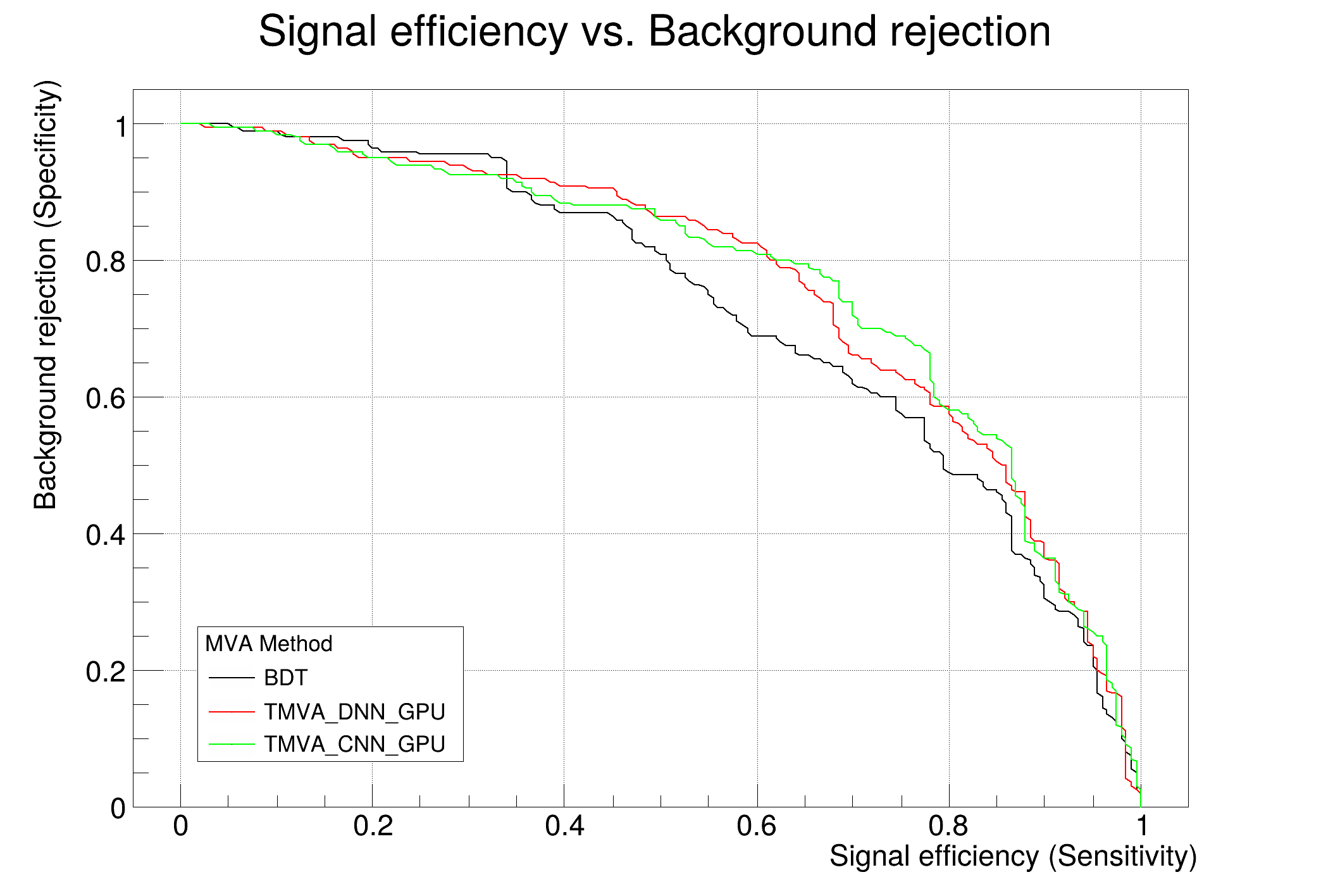
auto c1 = factory.GetROCCurve(&loader);
}
double Double_t
Double 8 bytes.
Error("WriteTObject","The current directory (%s) is not associated with a file. The object (%s) has not been written.", GetName(), objname)
void Info(const char *location, const char *msgfmt,...)
Use this function for informational messages.
void Warning(const char *location, const char *msgfmt,...)
Use this function in warning situations.
Option_t Option_t TPoint TPoint const char x2
Option_t Option_t TPoint TPoint const char x1
A specialized string object used for TTree selections.
static TFile * Open(const char *name, Option_t *option="", const char *ftitle="", Int_t compress=ROOT::RCompressionSetting::EDefaults::kUseCompiledDefault, Int_t netopt=0)
void Close(Option_t *option="") override
Delete all objects from memory and directory structure itself.
2-D histogram with a double per channel (see TH1 documentation)
This is the main MVA steering class.
static void PyInitialize()
Initialize Python interpreter.
Class supporting a collection of lines with C++ code.
const char * Data() const
static TString Format(const char *fmt,...)
Static method which formats a string using a printf style format descriptor and return a TString.
A TTree represents a columnar dataset.
virtual Long64_t GetEntries() const
void EnableImplicitMT(UInt_t numthreads=0)
Enable ROOT's implicit multi-threading for all objects and methods that provide an internal paralleli...
UInt_t GetThreadPoolSize()
Returns the size of ROOT's thread pool.
TString Python_Executable()
Function to find current Python executable used by ROOT If "Python3" is installed,...
Running with nthreads = 4
DataSetInfo : [dataset] : Added class "Signal"
: Add Tree sig_tree of type Signal with 1000 events
DataSetInfo : [dataset] : Added class "Background"
: Add Tree bkg_tree of type Background with 1000 events
Factory : Booking method: ␛[1mBDT␛[0m
:
: Rebuilding Dataset dataset
: Building event vectors for type 2 Signal
: Dataset[dataset] : create input formulas for tree sig_tree
: Using variable vars[0] from array expression vars of size 256
: Building event vectors for type 2 Background
: Dataset[dataset] : create input formulas for tree bkg_tree
: Using variable vars[0] from array expression vars of size 256
DataSetFactory : [dataset] : Number of events in input trees
:
:
: Number of training and testing events
: ---------------------------------------------------------------------------
: Signal -- training events : 800
: Signal -- testing events : 200
: Signal -- training and testing events: 1000
: Background -- training events : 800
: Background -- testing events : 200
: Background -- training and testing events: 1000
:
Factory : Booking method: ␛[1mTMVA_DNN_CPU␛[0m
:
: Parsing option string:
: ... "!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=None:WeightInitialization=XAVIER:Layout=DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,DENSE|1|LINEAR:TrainingStrategy=LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.:Architecture=CPU"
: The following options are set:
: - By User:
: <none>
: - Default:
: Boost_num: "0" [Number of times the classifier will be boosted]
: Parsing option string:
: ... "!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=None:WeightInitialization=XAVIER:Layout=DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,DENSE|1|LINEAR:TrainingStrategy=LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.:Architecture=CPU"
: The following options are set:
: - By User:
: V: "True" [Verbose output (short form of "VerbosityLevel" below - overrides the latter one)]
: VarTransform: "None" [List of variable transformations performed before training, e.g., "D_Background,P_Signal,G,N_AllClasses" for: "Decorrelation, PCA-transformation, Gaussianisation, Normalisation, each for the given class of events ('AllClasses' denotes all events of all classes, if no class indication is given, 'All' is assumed)"]
: H: "False" [Print method-specific help message]
: Layout: "DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,BNORM,DENSE|100|RELU,DENSE|1|LINEAR" [Layout of the network.]
: ErrorStrategy: "CROSSENTROPY" [Loss function: Mean squared error (regression) or cross entropy (binary classification).]
: WeightInitialization: "XAVIER" [Weight initialization strategy]
: Architecture: "CPU" [Which architecture to perform the training on.]
: TrainingStrategy: "LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0." [Defines the training strategies.]
: - Default:
: VerbosityLevel: "Default" [Verbosity level]
: CreateMVAPdfs: "False" [Create PDFs for classifier outputs (signal and background)]
: IgnoreNegWeightsInTraining: "False" [Events with negative weights are ignored in the training (but are included for testing and performance evaluation)]
: InputLayout: "0|0|0" [The Layout of the input]
: BatchLayout: "0|0|0" [The Layout of the batch]
: RandomSeed: "0" [Random seed used for weight initialization and batch shuffling]
: ValidationSize: "20%" [Part of the training data to use for validation. Specify as 0.2 or 20% to use a fifth of the data set as validation set. Specify as 100 to use exactly 100 events. (Default: 20%)]
: Will now use the CPU architecture with BLAS and IMT support !
Factory : Booking method: ␛[1mTMVA_CNN_CPU␛[0m
:
: Parsing option string:
: ... "!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=None:WeightInitialization=XAVIER:InputLayout=1|16|16:Layout=CONV|10|3|3|1|1|1|1|RELU,BNORM,CONV|10|3|3|1|1|1|1|RELU,MAXPOOL|2|2|1|1,RESHAPE|FLAT,DENSE|100|RELU,DENSE|1|LINEAR:TrainingStrategy=LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.0:Architecture=CPU"
: The following options are set:
: - By User:
: <none>
: - Default:
: Boost_num: "0" [Number of times the classifier will be boosted]
: Parsing option string:
: ... "!H:V:ErrorStrategy=CROSSENTROPY:VarTransform=None:WeightInitialization=XAVIER:InputLayout=1|16|16:Layout=CONV|10|3|3|1|1|1|1|RELU,BNORM,CONV|10|3|3|1|1|1|1|RELU,MAXPOOL|2|2|1|1,RESHAPE|FLAT,DENSE|100|RELU,DENSE|1|LINEAR:TrainingStrategy=LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.0:Architecture=CPU"
: The following options are set:
: - By User:
: V: "True" [Verbose output (short form of "VerbosityLevel" below - overrides the latter one)]
: VarTransform: "None" [List of variable transformations performed before training, e.g., "D_Background,P_Signal,G,N_AllClasses" for: "Decorrelation, PCA-transformation, Gaussianisation, Normalisation, each for the given class of events ('AllClasses' denotes all events of all classes, if no class indication is given, 'All' is assumed)"]
: H: "False" [Print method-specific help message]
: InputLayout: "1|16|16" [The Layout of the input]
: Layout: "CONV|10|3|3|1|1|1|1|RELU,BNORM,CONV|10|3|3|1|1|1|1|RELU,MAXPOOL|2|2|1|1,RESHAPE|FLAT,DENSE|100|RELU,DENSE|1|LINEAR" [Layout of the network.]
: ErrorStrategy: "CROSSENTROPY" [Loss function: Mean squared error (regression) or cross entropy (binary classification).]
: WeightInitialization: "XAVIER" [Weight initialization strategy]
: Architecture: "CPU" [Which architecture to perform the training on.]
: TrainingStrategy: "LearningRate=1e-3,Momentum=0.9,Repetitions=1,ConvergenceSteps=5,BatchSize=100,TestRepetitions=1,MaxEpochs=10,WeightDecay=1e-4,Regularization=None,Optimizer=ADAM,DropConfig=0.0+0.0+0.0+0.0" [Defines the training strategies.]
: - Default:
: VerbosityLevel: "Default" [Verbosity level]
: CreateMVAPdfs: "False" [Create PDFs for classifier outputs (signal and background)]
: IgnoreNegWeightsInTraining: "False" [Events with negative weights are ignored in the training (but are included for testing and performance evaluation)]
: BatchLayout: "0|0|0" [The Layout of the batch]
: RandomSeed: "0" [Random seed used for weight initialization and batch shuffling]
: ValidationSize: "20%" [Part of the training data to use for validation. Specify as 0.2 or 20% to use a fifth of the data set as validation set. Specify as 100 to use exactly 100 events. (Default: 20%)]
: Will now use the CPU architecture with BLAS and IMT support !
Factory : ␛[1mTrain all methods␛[0m
Factory : Train method: BDT for Classification
:
BDT : #events: (reweighted) sig: 800 bkg: 800
: #events: (unweighted) sig: 800 bkg: 800
: Training 200 Decision Trees ... patience please
: Elapsed time for training with 1600 events: ␛[1;31m0.765 sec␛[0m
BDT : [dataset] : Evaluation of BDT on training sample (1600 events)
BDT : [dataset] : Evaluation of BDT on training sample (1600 events)
: Elapsed time for evaluation of 1600 events: ␛[1;31m0.0146 sec␛[0m
: Elapsed time for evaluation of 1600 events: ␛[1;31m0.0147 sec␛[0m
: Creating xml weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_BDT.weights.xml␛[0m
: Creating standalone class: ␛[0;36mdataset/weights/TMVA_CNN_Classification_BDT.class.C␛[0m
: TMVA_CNN_ClassificationOutput.root:/dataset/Method_BDT/BDT
Factory : Training finished
:
Factory : Train method: TMVA_DNN_CPU for Classification
:
: Start of deep neural network training on CPU using MT, nthreads = 4
:
: ***** Deep Learning Network *****
DEEP NEURAL NETWORK: Depth = 8 Input = ( 1, 1, 256 ) Batch size = 100 Loss function = C
Layer 0 DENSE Layer: ( Input = 256 , Width = 100 ) Output = ( 1 , 100 , 100 ) Activation Function = Relu
Layer 1 BATCH NORM Layer: Input/Output = ( 100 , 100 , 1 ) Norm dim = 100 axis = -1
Layer 2 DENSE Layer: ( Input = 100 , Width = 100 ) Output = ( 1 , 100 , 100 ) Activation Function = Relu
Layer 3 BATCH NORM Layer: Input/Output = ( 100 , 100 , 1 ) Norm dim = 100 axis = -1
Layer 4 DENSE Layer: ( Input = 100 , Width = 100 ) Output = ( 1 , 100 , 100 ) Activation Function = Relu
Layer 5 BATCH NORM Layer: Input/Output = ( 100 , 100 , 1 ) Norm dim = 100 axis = -1
Layer 6 DENSE Layer: ( Input = 100 , Width = 100 ) Output = ( 1 , 100 , 100 ) Activation Function = Relu
Layer 7 DENSE Layer: ( Input = 100 , Width = 1 ) Output = ( 1 , 100 , 1 ) Activation Function = Identity
: Using 1280 events for training and 320 for testing
: Compute initial loss on the validation data
: Training phase 1 of 1: Optimizer ADAM (beta1=0.9,beta2=0.999,eps=1e-07) Learning rate = 0.001 regularization 0 minimum error = 85.2457
: --------------------------------------------------------------
: Epoch | Train Err. Val. Err. t(s)/epoch t(s)/Loss nEvents/s Conv. Steps
: --------------------------------------------------------------
: Start epoch iteration ...
: 1 Minimum Test error found - save the configuration
: 1 | 0.952233 0.814394 0.144186 0.0164521 9394.55 0
: 2 Minimum Test error found - save the configuration
: 2 | 0.68909 0.776758 0.160462 0.0155186 8279.12 0
: 3 Minimum Test error found - save the configuration
: 3 | 0.601306 0.71145 0.163029 0.0145404 8081.43 0
: 4 | 0.539186 0.725519 0.148748 0.0148666 8963.13 1
: 5 | 0.461339 0.733359 0.157867 0.0132863 8299.88 2
: 6 | 0.415903 0.717694 0.140092 0.0106639 9271.56 3
: 7 Minimum Test error found - save the configuration
: 7 | 0.377871 0.684682 0.124198 0.0106623 10569.3 0
: 8 | 0.312582 0.687467 0.126619 0.012176 10485.6 1
: 9 | 0.275817 0.715478 0.138779 0.0121312 9475.12 2
: 10 Minimum Test error found - save the configuration
: 10 | 0.232059 0.683726 0.140478 0.0120469 9343.5 0
:
: Elapsed time for training with 1600 events: ␛[1;31m1.47 sec␛[0m
TMVA_DNN_CPU : [dataset] : Evaluation of TMVA_DNN_CPU on training sample (1600 events)
: Evaluate deep neural network on CPU using batches with size = 100
:
TMVA_DNN_CPU : [dataset] : Evaluation of TMVA_DNN_CPU on training sample (1600 events)
: Elapsed time for evaluation of 1600 events: ␛[1;31m0.0538 sec␛[0m
: Elapsed time for evaluation of 1600 events: ␛[1;31m0.0556 sec␛[0m
: Creating xml weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_DNN_CPU.weights.xml␛[0m
: Creating standalone class: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_DNN_CPU.class.C␛[0m
Factory : Training finished
:
Factory : Train method: TMVA_CNN_CPU for Classification
:
: Start of deep neural network training on CPU using MT, nthreads = 4
:
: ***** Deep Learning Network *****
DEEP NEURAL NETWORK: Depth = 7 Input = ( 1, 16, 16 ) Batch size = 100 Loss function = C
Layer 0 CONV LAYER: ( W = 16 , H = 16 , D = 10 ) Filter ( W = 3 , H = 3 ) Output = ( 100 , 10 , 10 , 256 ) Activation Function = Relu
Layer 1 BATCH NORM Layer: Input/Output = ( 10 , 256 , 100 ) Norm dim = 10 axis = 1
Layer 2 CONV LAYER: ( W = 16 , H = 16 , D = 10 ) Filter ( W = 3 , H = 3 ) Output = ( 100 , 10 , 10 , 256 ) Activation Function = Relu
Layer 3 POOL Layer: ( W = 15 , H = 15 , D = 10 ) Filter ( W = 2 , H = 2 ) Output = ( 100 , 10 , 10 , 225 )
Layer 4 RESHAPE Layer Input = ( 10 , 15 , 15 ) Output = ( 1 , 100 , 2250 )
Layer 5 DENSE Layer: ( Input = 2250 , Width = 100 ) Output = ( 1 , 100 , 100 ) Activation Function = Relu
Layer 6 DENSE Layer: ( Input = 100 , Width = 1 ) Output = ( 1 , 100 , 1 ) Activation Function = Identity
: Using 1280 events for training and 320 for testing
: Compute initial loss on the validation data
: Training phase 1 of 1: Optimizer ADAM (beta1=0.9,beta2=0.999,eps=1e-07) Learning rate = 0.001 regularization 0 minimum error = 83.8752
: --------------------------------------------------------------
: Epoch | Train Err. Val. Err. t(s)/epoch t(s)/Loss nEvents/s Conv. Steps
: --------------------------------------------------------------
: Start epoch iteration ...
: 1 Minimum Test error found - save the configuration
: 1 | 2.44175 1.17371 1.35578 0.150791 995.862 0
: 2 Minimum Test error found - save the configuration
: 2 | 0.931791 0.813603 1.2757 0.0935187 1015.07 0
: 3 Minimum Test error found - save the configuration
: 3 | 0.768733 0.720823 1.03986 0.0875235 1260.05 0
: 4 Minimum Test error found - save the configuration
: 4 | 0.704782 0.701576 1.2483 0.122807 1066.2 0
: 5 Minimum Test error found - save the configuration
: 5 | 0.686119 0.693182 1.80683 0.176114 735.872 0
: 6 Minimum Test error found - save the configuration
: 6 | 0.67436 0.68059 1.33529 0.121178 988.373 0
: 7 Minimum Test error found - save the configuration
: 7 | 0.659917 0.666153 1.2585 0.113986 1048.48 0
: 8 Minimum Test error found - save the configuration
: 8 | 0.644404 0.643599 1.29515 0.10722 1010.16 0
: 9 Minimum Test error found - save the configuration
: 9 | 0.620873 0.641937 1.26159 0.123011 1053.95 0
: 10 Minimum Test error found - save the configuration
: 10 | 0.595598 0.633936 1.32011 0.124121 1003.36 0
:
: Elapsed time for training with 1600 events: ␛[1;31m13.3 sec␛[0m
TMVA_CNN_CPU : [dataset] : Evaluation of TMVA_CNN_CPU on training sample (1600 events)
: Evaluate deep neural network on CPU using batches with size = 100
:
TMVA_CNN_CPU : [dataset] : Evaluation of TMVA_CNN_CPU on training sample (1600 events)
: Elapsed time for evaluation of 1600 events: ␛[1;31m0.616 sec␛[0m
: Elapsed time for evaluation of 1600 events: ␛[1;31m0.626 sec␛[0m
: Creating xml weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_CNN_CPU.weights.xml␛[0m
: Creating standalone class: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_CNN_CPU.class.C␛[0m
Factory : Training finished
:
: Ranking input variables (method specific)...
BDT : Ranking result (top variable is best ranked)
: --------------------------------------
: Rank : Variable : Variable Importance
: --------------------------------------
: 1 : vars : 1.048e-02
: 2 : vars : 9.756e-03
: 3 : vars : 9.505e-03
: 4 : vars : 9.489e-03
: 5 : vars : 9.228e-03
: 6 : vars : 9.095e-03
: 7 : vars : 8.800e-03
: 8 : vars : 8.777e-03
: 9 : vars : 8.644e-03
: 10 : vars : 8.207e-03
: 11 : vars : 8.184e-03
: 12 : vars : 8.039e-03
: 13 : vars : 8.018e-03
: 14 : vars : 7.998e-03
: 15 : vars : 7.981e-03
: 16 : vars : 7.965e-03
: 17 : vars : 7.918e-03
: 18 : vars : 7.573e-03
: 19 : vars : 7.515e-03
: 20 : vars : 7.512e-03
: 21 : vars : 7.440e-03
: 22 : vars : 7.406e-03
: 23 : vars : 7.397e-03
: 24 : vars : 7.362e-03
: 25 : vars : 7.336e-03
: 26 : vars : 7.258e-03
: 27 : vars : 7.211e-03
: 28 : vars : 7.151e-03
: 29 : vars : 7.122e-03
: 30 : vars : 7.053e-03
: 31 : vars : 6.988e-03
: 32 : vars : 6.976e-03
: 33 : vars : 6.962e-03
: 34 : vars : 6.848e-03
: 35 : vars : 6.839e-03
: 36 : vars : 6.836e-03
: 37 : vars : 6.785e-03
: 38 : vars : 6.724e-03
: 39 : vars : 6.648e-03
: 40 : vars : 6.456e-03
: 41 : vars : 6.401e-03
: 42 : vars : 6.395e-03
: 43 : vars : 6.358e-03
: 44 : vars : 6.235e-03
: 45 : vars : 6.234e-03
: 46 : vars : 6.172e-03
: 47 : vars : 6.156e-03
: 48 : vars : 6.127e-03
: 49 : vars : 6.099e-03
: 50 : vars : 6.084e-03
: 51 : vars : 6.081e-03
: 52 : vars : 6.067e-03
: 53 : vars : 6.045e-03
: 54 : vars : 6.006e-03
: 55 : vars : 5.901e-03
: 56 : vars : 5.862e-03
: 57 : vars : 5.857e-03
: 58 : vars : 5.846e-03
: 59 : vars : 5.798e-03
: 60 : vars : 5.751e-03
: 61 : vars : 5.744e-03
: 62 : vars : 5.739e-03
: 63 : vars : 5.700e-03
: 64 : vars : 5.692e-03
: 65 : vars : 5.666e-03
: 66 : vars : 5.638e-03
: 67 : vars : 5.620e-03
: 68 : vars : 5.613e-03
: 69 : vars : 5.568e-03
: 70 : vars : 5.548e-03
: 71 : vars : 5.465e-03
: 72 : vars : 5.442e-03
: 73 : vars : 5.440e-03
: 74 : vars : 5.423e-03
: 75 : vars : 5.422e-03
: 76 : vars : 5.417e-03
: 77 : vars : 5.388e-03
: 78 : vars : 5.379e-03
: 79 : vars : 5.379e-03
: 80 : vars : 5.333e-03
: 81 : vars : 5.318e-03
: 82 : vars : 5.313e-03
: 83 : vars : 5.242e-03
: 84 : vars : 5.199e-03
: 85 : vars : 5.181e-03
: 86 : vars : 5.122e-03
: 87 : vars : 5.062e-03
: 88 : vars : 5.004e-03
: 89 : vars : 4.965e-03
: 90 : vars : 4.941e-03
: 91 : vars : 4.900e-03
: 92 : vars : 4.888e-03
: 93 : vars : 4.852e-03
: 94 : vars : 4.845e-03
: 95 : vars : 4.844e-03
: 96 : vars : 4.820e-03
: 97 : vars : 4.787e-03
: 98 : vars : 4.775e-03
: 99 : vars : 4.768e-03
: 100 : vars : 4.759e-03
: 101 : vars : 4.740e-03
: 102 : vars : 4.714e-03
: 103 : vars : 4.684e-03
: 104 : vars : 4.680e-03
: 105 : vars : 4.645e-03
: 106 : vars : 4.638e-03
: 107 : vars : 4.617e-03
: 108 : vars : 4.594e-03
: 109 : vars : 4.590e-03
: 110 : vars : 4.564e-03
: 111 : vars : 4.562e-03
: 112 : vars : 4.534e-03
: 113 : vars : 4.533e-03
: 114 : vars : 4.531e-03
: 115 : vars : 4.498e-03
: 116 : vars : 4.448e-03
: 117 : vars : 4.426e-03
: 118 : vars : 4.424e-03
: 119 : vars : 4.420e-03
: 120 : vars : 4.419e-03
: 121 : vars : 4.402e-03
: 122 : vars : 4.342e-03
: 123 : vars : 4.273e-03
: 124 : vars : 4.265e-03
: 125 : vars : 4.179e-03
: 126 : vars : 4.122e-03
: 127 : vars : 4.084e-03
: 128 : vars : 4.082e-03
: 129 : vars : 4.081e-03
: 130 : vars : 4.081e-03
: 131 : vars : 4.061e-03
: 132 : vars : 4.049e-03
: 133 : vars : 4.023e-03
: 134 : vars : 3.951e-03
: 135 : vars : 3.927e-03
: 136 : vars : 3.923e-03
: 137 : vars : 3.875e-03
: 138 : vars : 3.875e-03
: 139 : vars : 3.865e-03
: 140 : vars : 3.823e-03
: 141 : vars : 3.809e-03
: 142 : vars : 3.766e-03
: 143 : vars : 3.727e-03
: 144 : vars : 3.715e-03
: 145 : vars : 3.692e-03
: 146 : vars : 3.655e-03
: 147 : vars : 3.654e-03
: 148 : vars : 3.637e-03
: 149 : vars : 3.632e-03
: 150 : vars : 3.622e-03
: 151 : vars : 3.575e-03
: 152 : vars : 3.552e-03
: 153 : vars : 3.449e-03
: 154 : vars : 3.443e-03
: 155 : vars : 3.439e-03
: 156 : vars : 3.408e-03
: 157 : vars : 3.387e-03
: 158 : vars : 3.384e-03
: 159 : vars : 3.297e-03
: 160 : vars : 3.286e-03
: 161 : vars : 3.273e-03
: 162 : vars : 3.266e-03
: 163 : vars : 3.254e-03
: 164 : vars : 3.252e-03
: 165 : vars : 3.224e-03
: 166 : vars : 3.169e-03
: 167 : vars : 3.166e-03
: 168 : vars : 3.161e-03
: 169 : vars : 3.139e-03
: 170 : vars : 3.095e-03
: 171 : vars : 3.028e-03
: 172 : vars : 3.025e-03
: 173 : vars : 3.014e-03
: 174 : vars : 2.991e-03
: 175 : vars : 2.983e-03
: 176 : vars : 2.964e-03
: 177 : vars : 2.847e-03
: 178 : vars : 2.805e-03
: 179 : vars : 2.778e-03
: 180 : vars : 2.771e-03
: 181 : vars : 2.765e-03
: 182 : vars : 2.726e-03
: 183 : vars : 2.577e-03
: 184 : vars : 2.540e-03
: 185 : vars : 2.536e-03
: 186 : vars : 2.495e-03
: 187 : vars : 2.469e-03
: 188 : vars : 2.378e-03
: 189 : vars : 2.338e-03
: 190 : vars : 2.326e-03
: 191 : vars : 2.252e-03
: 192 : vars : 2.245e-03
: 193 : vars : 2.232e-03
: 194 : vars : 2.149e-03
: 195 : vars : 2.031e-03
: 196 : vars : 2.027e-03
: 197 : vars : 1.966e-03
: 198 : vars : 1.909e-03
: 199 : vars : 1.894e-03
: 200 : vars : 1.618e-03
: 201 : vars : 1.588e-03
: 202 : vars : 1.342e-03
: 203 : vars : 1.291e-03
: 204 : vars : 1.231e-03
: 205 : vars : 9.310e-04
: 206 : vars : 1.030e-04
: 207 : vars : 0.000e+00
: 208 : vars : 0.000e+00
: 209 : vars : 0.000e+00
: 210 : vars : 0.000e+00
: 211 : vars : 0.000e+00
: 212 : vars : 0.000e+00
: 213 : vars : 0.000e+00
: 214 : vars : 0.000e+00
: 215 : vars : 0.000e+00
: 216 : vars : 0.000e+00
: 217 : vars : 0.000e+00
: 218 : vars : 0.000e+00
: 219 : vars : 0.000e+00
: 220 : vars : 0.000e+00
: 221 : vars : 0.000e+00
: 222 : vars : 0.000e+00
: 223 : vars : 0.000e+00
: 224 : vars : 0.000e+00
: 225 : vars : 0.000e+00
: 226 : vars : 0.000e+00
: 227 : vars : 0.000e+00
: 228 : vars : 0.000e+00
: 229 : vars : 0.000e+00
: 230 : vars : 0.000e+00
: 231 : vars : 0.000e+00
: 232 : vars : 0.000e+00
: 233 : vars : 0.000e+00
: 234 : vars : 0.000e+00
: 235 : vars : 0.000e+00
: 236 : vars : 0.000e+00
: 237 : vars : 0.000e+00
: 238 : vars : 0.000e+00
: 239 : vars : 0.000e+00
: 240 : vars : 0.000e+00
: 241 : vars : 0.000e+00
: 242 : vars : 0.000e+00
: 243 : vars : 0.000e+00
: 244 : vars : 0.000e+00
: 245 : vars : 0.000e+00
: 246 : vars : 0.000e+00
: 247 : vars : 0.000e+00
: 248 : vars : 0.000e+00
: 249 : vars : 0.000e+00
: 250 : vars : 0.000e+00
: 251 : vars : 0.000e+00
: 252 : vars : 0.000e+00
: 253 : vars : 0.000e+00
: 254 : vars : 0.000e+00
: 255 : vars : 0.000e+00
: 256 : vars : 0.000e+00
: --------------------------------------
: No variable ranking supplied by classifier: TMVA_DNN_CPU
: No variable ranking supplied by classifier: TMVA_CNN_CPU
TH1.Print Name = TrainingHistory_TMVA_DNN_CPU_trainingError, Entries= 0, Total sum= 4.85739
TH1.Print Name = TrainingHistory_TMVA_DNN_CPU_valError, Entries= 0, Total sum= 7.25053
TH1.Print Name = TrainingHistory_TMVA_CNN_CPU_trainingError, Entries= 0, Total sum= 8.72832
TH1.Print Name = TrainingHistory_TMVA_CNN_CPU_valError, Entries= 0, Total sum= 7.36911
Factory : === Destroy and recreate all methods via weight files for testing ===
:
: Reading weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_BDT.weights.xml␛[0m
: Reading weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_DNN_CPU.weights.xml␛[0m
: Reading weight file: ␛[0;36mdataset/weights/TMVA_CNN_Classification_TMVA_CNN_CPU.weights.xml␛[0m
Factory : ␛[1mTest all methods␛[0m
Factory : Test method: BDT for Classification performance
:
BDT : [dataset] : Evaluation of BDT on testing sample (400 events)
BDT : [dataset] : Evaluation of BDT on testing sample (400 events)
: Elapsed time for evaluation of 400 events: ␛[1;31m0.00995 sec␛[0m
: Elapsed time for evaluation of 400 events: ␛[1;31m0.0101 sec␛[0m
Factory : Test method: TMVA_DNN_CPU for Classification performance
:
TMVA_DNN_CPU : [dataset] : Evaluation of TMVA_DNN_CPU on testing sample (400 events)
: Evaluate deep neural network on CPU using batches with size = 400
:
TMVA_DNN_CPU : [dataset] : Evaluation of TMVA_DNN_CPU on testing sample (400 events)
: Elapsed time for evaluation of 400 events: ␛[1;31m0.0191 sec␛[0m
: Elapsed time for evaluation of 400 events: ␛[1;31m0.0216 sec␛[0m
Factory : Test method: TMVA_CNN_CPU for Classification performance
:
TMVA_CNN_CPU : [dataset] : Evaluation of TMVA_CNN_CPU on testing sample (400 events)
: Evaluate deep neural network on CPU using batches with size = 400
:
TMVA_CNN_CPU : [dataset] : Evaluation of TMVA_CNN_CPU on testing sample (400 events)
: Elapsed time for evaluation of 400 events: ␛[1;31m0.174 sec␛[0m
: Elapsed time for evaluation of 400 events: ␛[1;31m0.188 sec␛[0m
Factory : ␛[1mEvaluate all methods␛[0m
Factory : Evaluate classifier: BDT
:
BDT : [dataset] : Loop over test events and fill histograms with classifier response...
:
: Dataset[dataset] : variable plots are not produces ! The number of variables is 256 , it is larger than 200
Factory : Evaluate classifier: TMVA_DNN_CPU
:
TMVA_DNN_CPU : [dataset] : Loop over test events and fill histograms with classifier response...
:
: Evaluate deep neural network on CPU using batches with size = 1000
:
: Dataset[dataset] : variable plots are not produces ! The number of variables is 256 , it is larger than 200
Factory : Evaluate classifier: TMVA_CNN_CPU
:
TMVA_CNN_CPU : [dataset] : Loop over test events and fill histograms with classifier response...
:
: Evaluate deep neural network on CPU using batches with size = 1000
:
: Dataset[dataset] : variable plots are not produces ! The number of variables is 256 , it is larger than 200
:
: Evaluation results ranked by best signal efficiency and purity (area)
: -------------------------------------------------------------------------------------------------------------------
: DataSet MVA
: Name: Method: ROC-integ
: dataset BDT : 0.747
: dataset TMVA_CNN_CPU : 0.736
: dataset TMVA_DNN_CPU : 0.654
: -------------------------------------------------------------------------------------------------------------------
:
: Testing efficiency compared to training efficiency (overtraining check)
: -------------------------------------------------------------------------------------------------------------------
: DataSet MVA Signal efficiency: from test sample (from training sample)
: Name: Method: @B=0.01 @B=0.10 @B=0.30
: -------------------------------------------------------------------------------------------------------------------
: dataset BDT : 0.095 (0.375) 0.400 (0.685) 0.648 (0.848)
: dataset TMVA_CNN_CPU : 0.045 (0.105) 0.358 (0.397) 0.657 (0.687)
: dataset TMVA_DNN_CPU : 0.047 (0.180) 0.225 (0.498) 0.485 (0.721)
: -------------------------------------------------------------------------------------------------------------------
:
Dataset:dataset : Created tree 'TestTree' with 400 events
:
Dataset:dataset : Created tree 'TrainTree' with 1600 events
:
Factory : ␛[1mThank you for using TMVA!␛[0m
: ␛[1mFor citation information, please visit: http://tmva.sf.net/citeTMVA.html␛[0m